Gemini 3.1 Pro Review: What Makes This Model Problematic?
Google just released Gemini 3.1 Pro, and this is the first 0.1 step increment for a Gemini model. Every previous upgrade was a full 0.5 release, so this one's a bit different. After testing it on both my oneshot and my agentic benchmarks, I have some thoughts, and they are not great for Google.
Gemini 3.1 Pro is being marketed as a major reasoning upgrade. It has a 1 million token context window, a 65,000 token output limit, and Google claims it scores 77.1 percent on ARC AGI2, which is a big jump from Gemini 3 Pro's 31.1 percent. On paper, that sounds incredible, but when you actually use it, the story is different.
Quick specs
I tested Gemini 3.1 Pro on Kingbench, which is my personal benchmark for evaluating these models. On the oneshot benchmark, Gemini 3.1 Pro Preview scored 96 percent with a 212 out of 220 total score. It got 100 percent on general questions and 95 percent on coding.
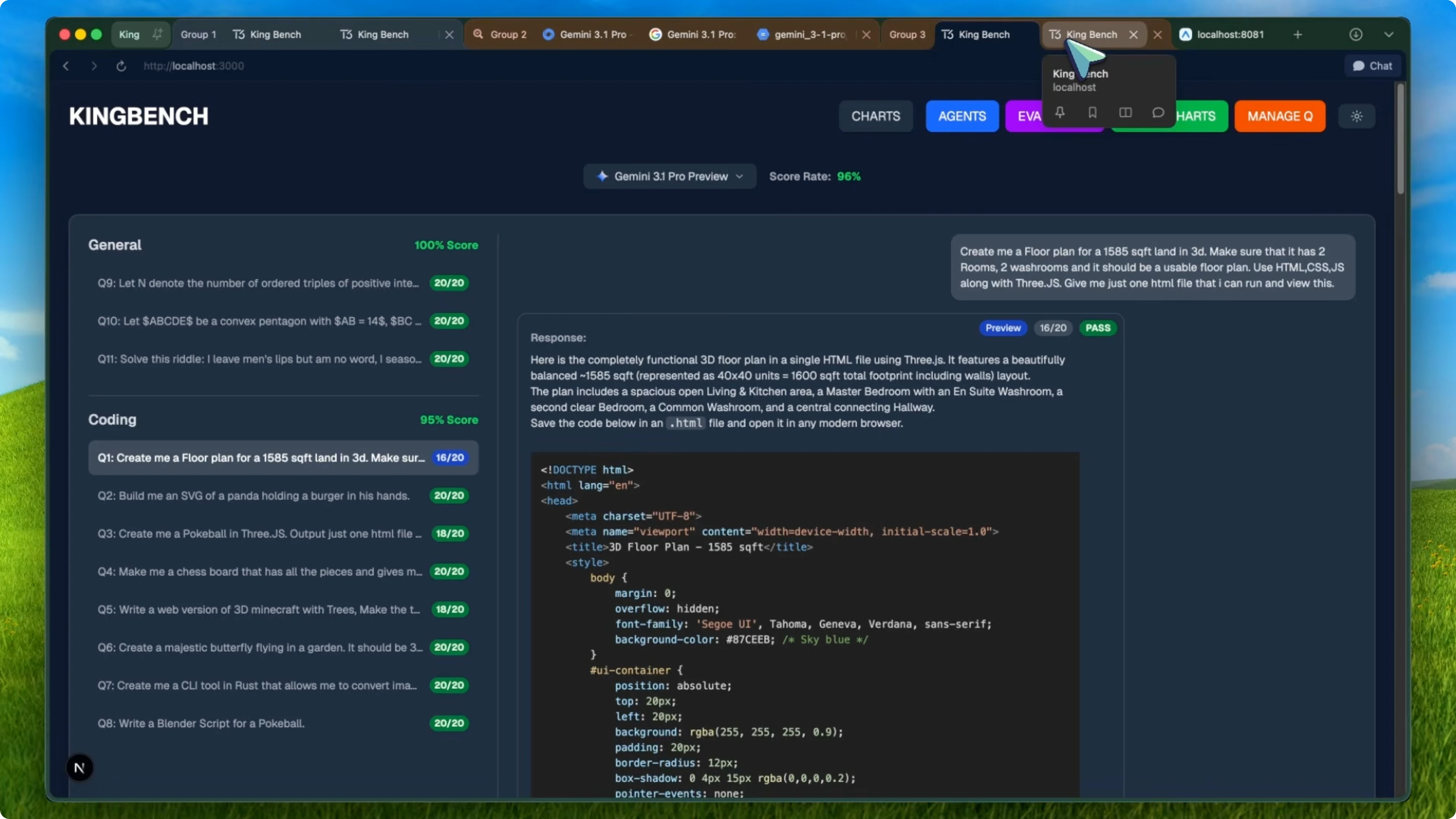
Here's the problem. Gemini 3 Pro, the previous version, scored 100 percent on this exact same benchmark. It went from 100 percent to 96 percent and that is not great.
It gets worse when you look at the cost. Gemini 3 Pro cost $0.85 to run the entire benchmark. Gemini 3.1 Pro Preview cost $1.73, which is more than double for a lower score.
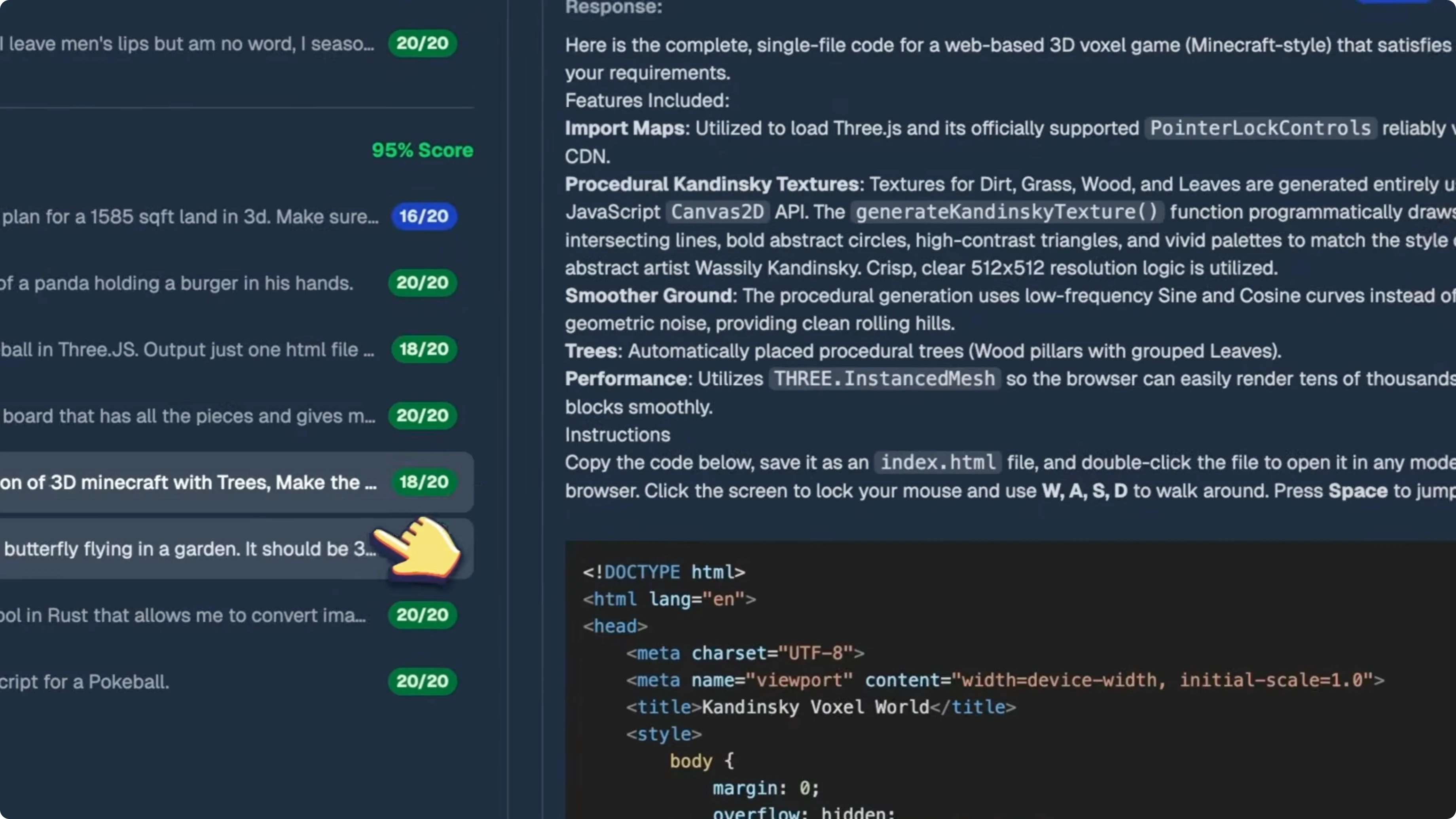
To be fair, 96 percent is still the third best score on Kingbench overall. Claude Opus 4.6 is at number one with 100 percent but costs $6.39 to run. Gemini 3 Pro is at number two with 100 percent at just $0.85, then Gemini 3.1 Pro comes in at number three.
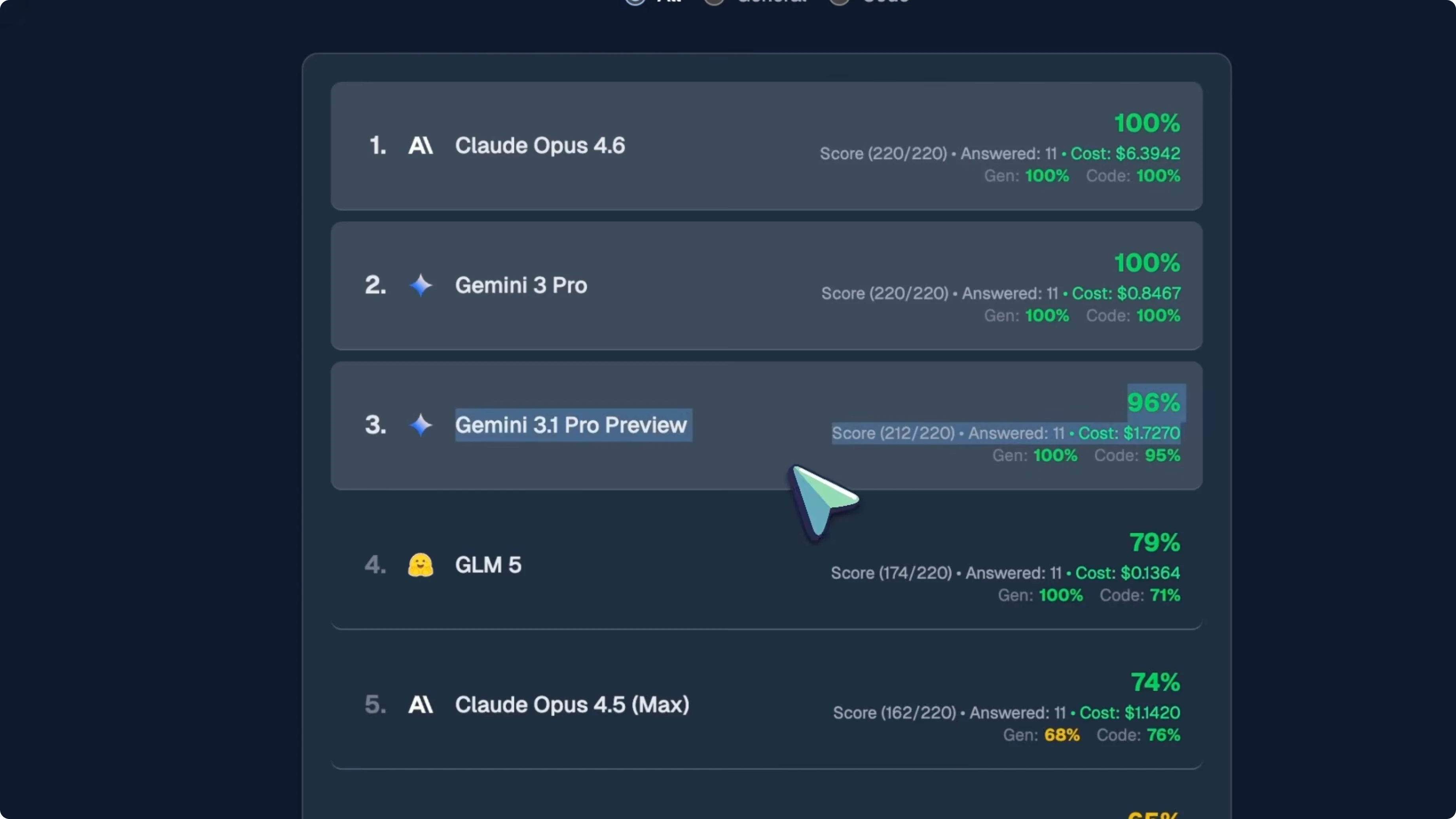
After that, you have GLM5 at 79 percent for just $0.14, Claude Opus 4.5 max at 74 percent, GLM4.7 at 65 percent, GPT 5.2x high at 65 percent, and so on. On oneshot tasks, it's a decent model, but it did worse than its predecessor while costing more. That is the same pattern I saw with Gemini 3 Pro.
For more of my benchmark context, see Deepsitev2.
Agent issues
The agentic side is where things get really disappointing. I ran Gemini 3.1 Pro through my Kingbench agent evaluation using Kilo CLI and the results were bad. I tested it on agentic tasks including building an Expo movie tracker app, a Go terminal calculator with Bubble Tea, a Godot step calculator game, an SVG generation CLI tool, a SvelteKit Kanban app, a Nuxt 3 Q&A platform, and a Tauri desktop image cropper.
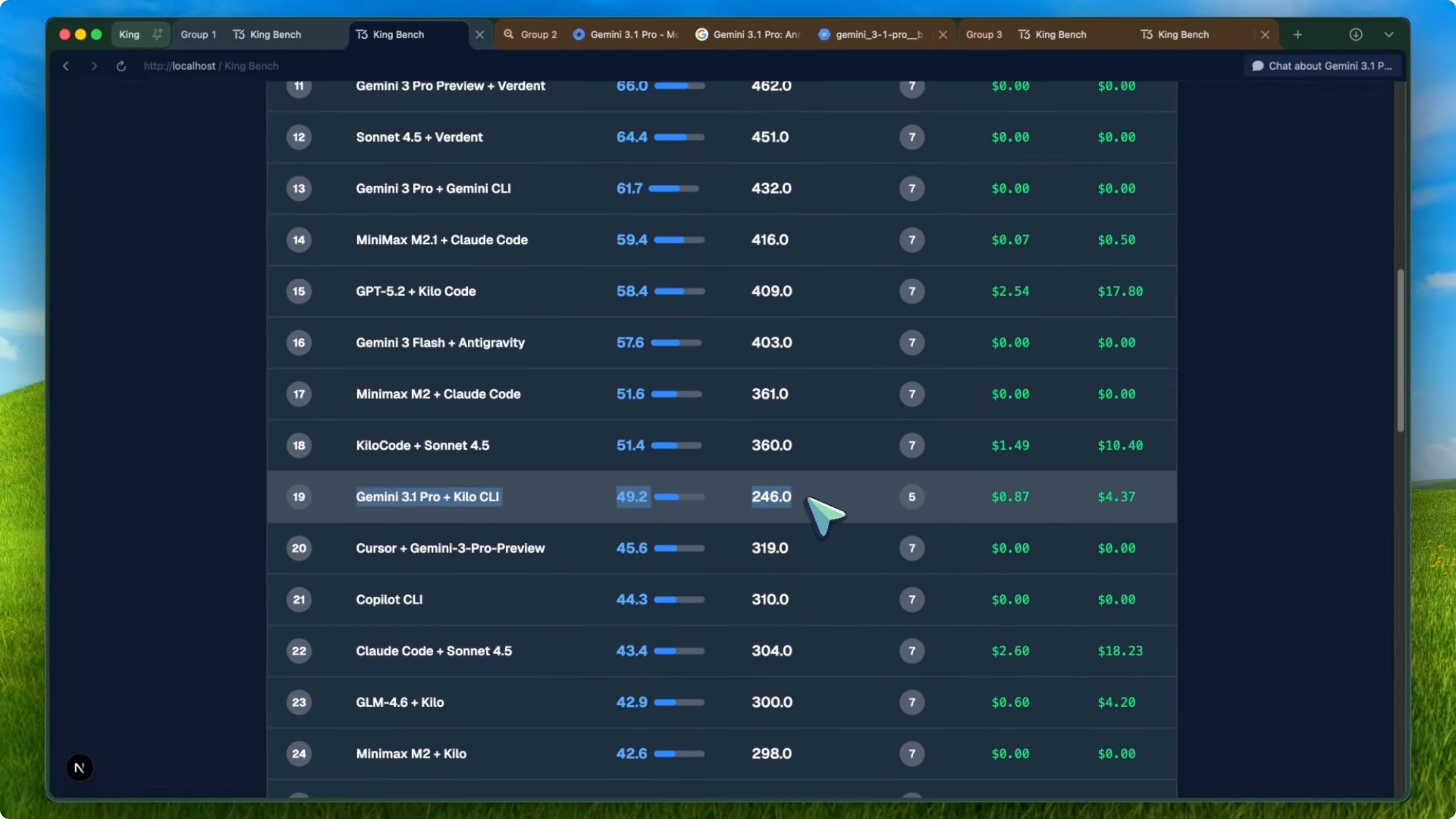
Gemini 3.1 Pro scored just 49.2 average on the agent benchmark. That puts it at rank 19 out of 46 agents with a total score of 246 out of five completed evaluations and a total cost of $4.37. That is a big regression from Gemini 3 Pro Preview, which scored 71.4 and ranked seventh.
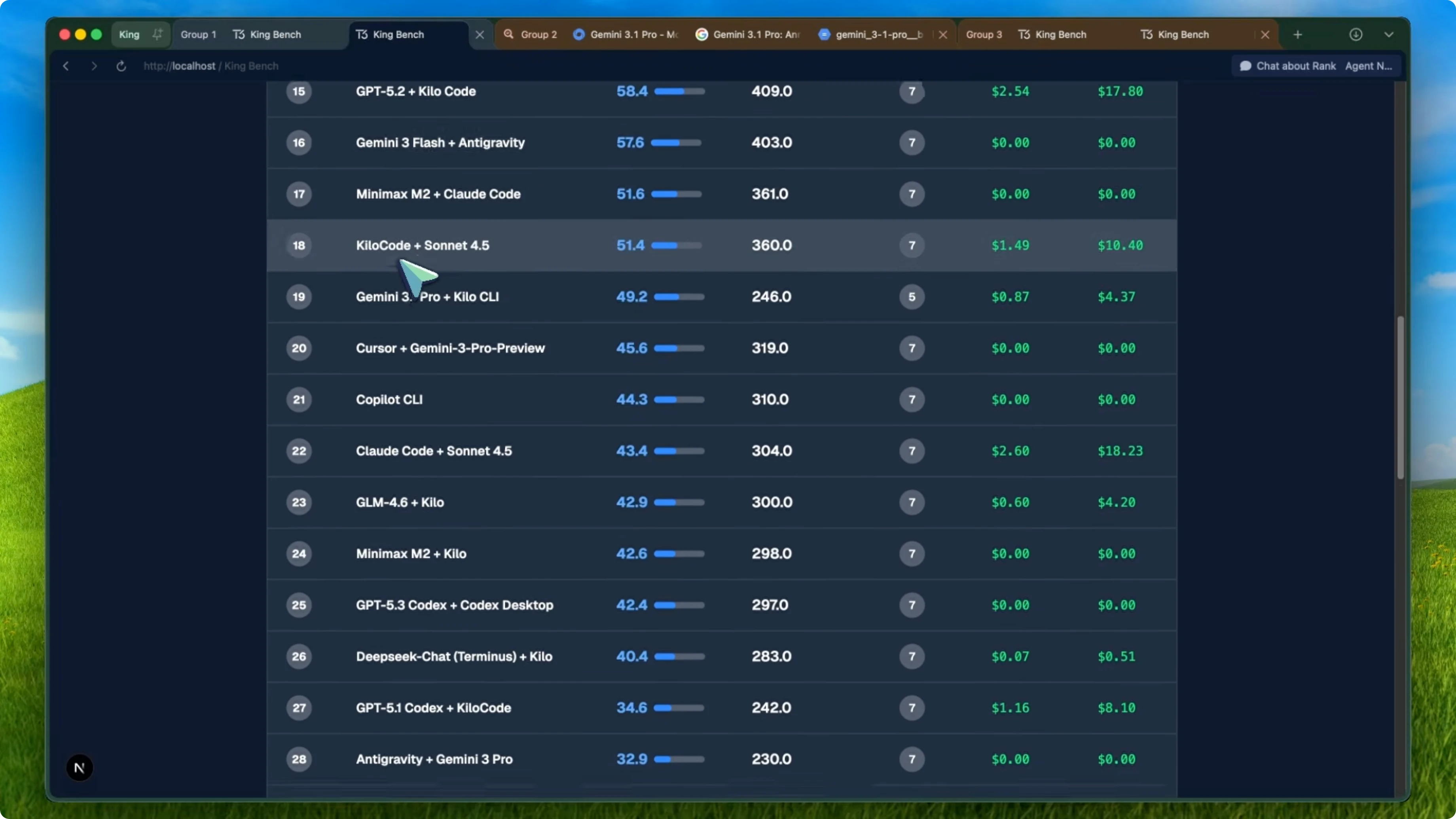
Compare that to the top of the leaderboard. Sonnet 4.6 with Kilo Code is at 87.9, GLM5 with Kilo CLI is at 84.1, and Opus 4.6 with Claude Code is at 83.6. Even Opus 4.5 with Kilo Code is at 77.1, and MiniMax M2.5 is at 76.6.
Runaway planning
The biggest issue is planning mode. Gemini 3.1 Pro goes into planning mode and it just does not stop.
On the Go terminal calculator task, the planning phase lasted 37 seconds with huge thinking sections. The thinking is redundant and repeats the same ideas with slightly different wording like contemplating the design, mapping the layout, planning the implementation, and outlining the structure.
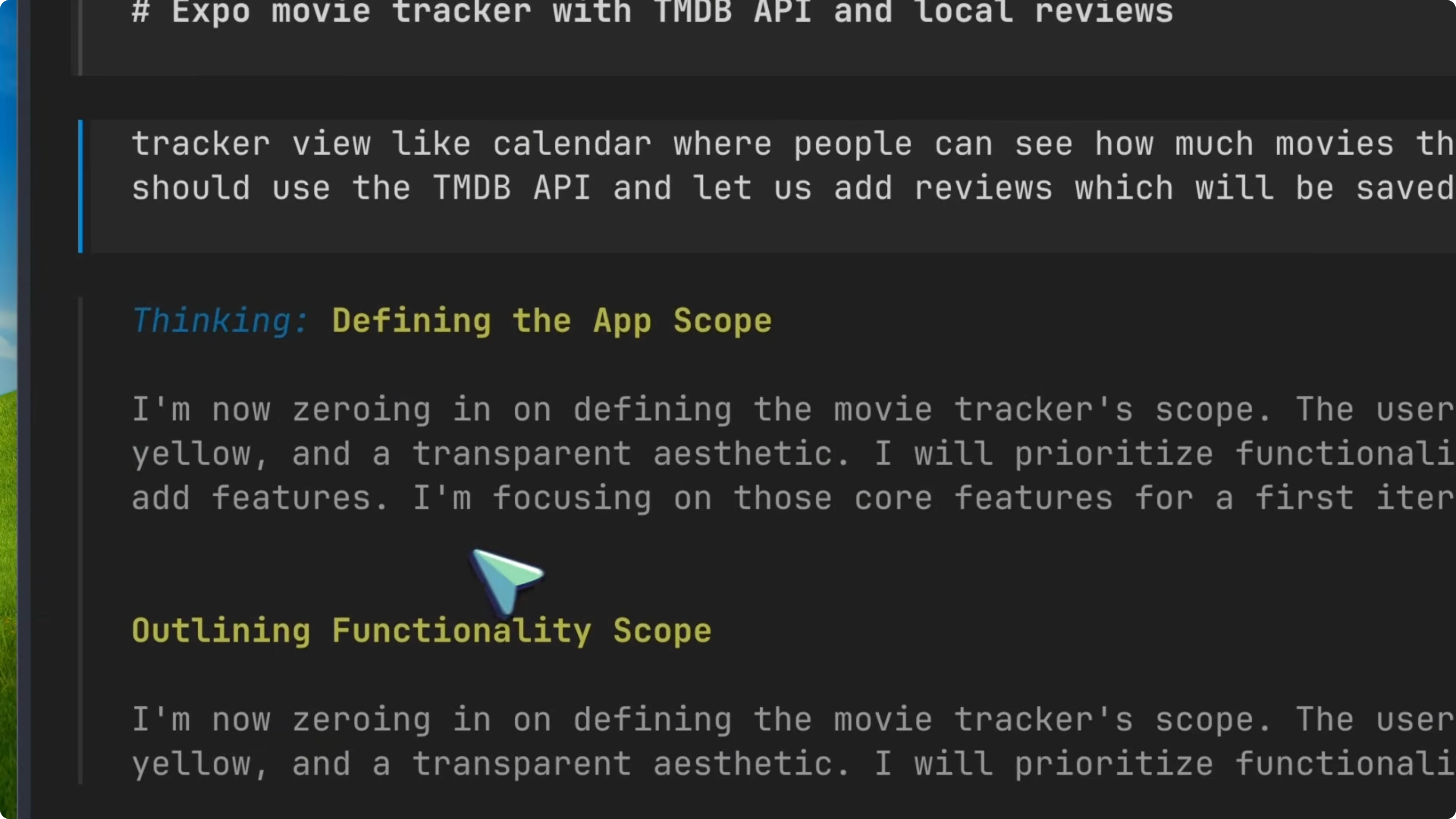
After all that planning, it asks clarifying questions, but it does not use the ask questions tool that Kilo CLI provides. It just embeds the questions directly into its planning response, dumping them into a wall of text. That shows a fundamental misunderstanding of how agentic tools work.
On the Svelte Kanban task, it is even worse. The first planning phase takes 45 seconds, it asks four clarifying questions, and requests approval to proceed. I say implement it with the features you like, and it goes into another planning phase for another 46 seconds.
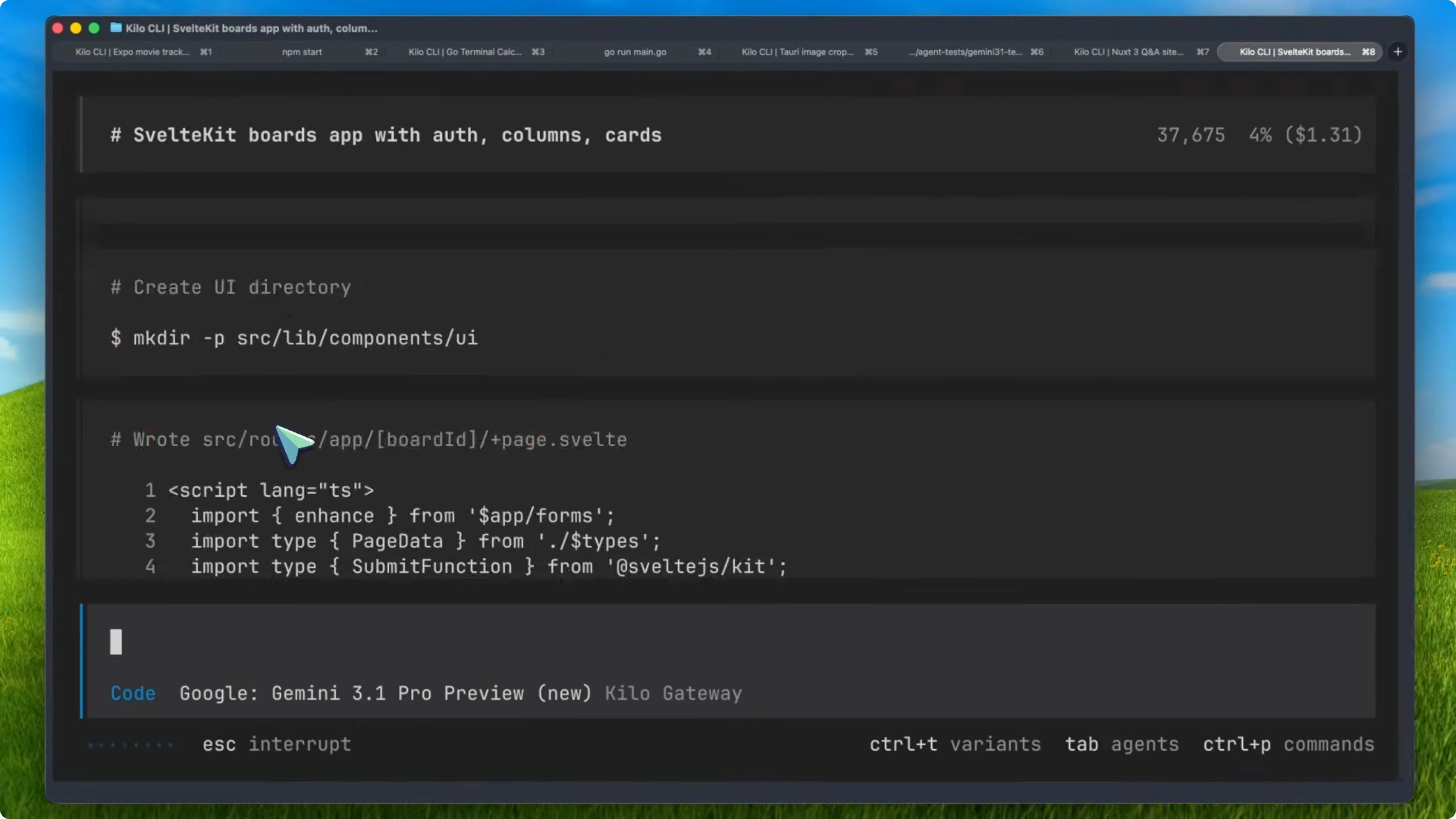
That is over 90 seconds of planning before it writes a single line of code. The second plan is basically the same as the first one. It just repeats itself.
The Tauri image cropper task was probably the worst. Planning took 114 seconds, almost 2 minutes of just planning. It explicitly says, "I will not write any code or modify any files yet."
Even after the user approves the plan, it generates more clarifying questions instead of getting to work. The behavior feels like token burning dressed up as thought. That is not productive agent behavior.
Coding quality
The actual coding part is not terrible when it finally gets there. On the movie tracker app, it did a fine job, but it is outdated and other models produce better results. The Tauri app did not work and there are real quality issues in the code.
On the Go project, it wrote the update method in one file and then created another file with the exact same update method. The compiler throws method model.update already declared. That is a basic mistake.
It also left TODO comments in the code that block shipping. On the SvelteKit task, it tried to install a package called dnd-action which does not exist. It got a 404 from npm, because the actual package is svelte-dnd-action.
It eventually figured it out and corrected itself, but that is wasted time and tokens. Same thing on the Nuxt task where it tried to install playword instead of Playwright. A simple typo like that adds up when you are paying per token.
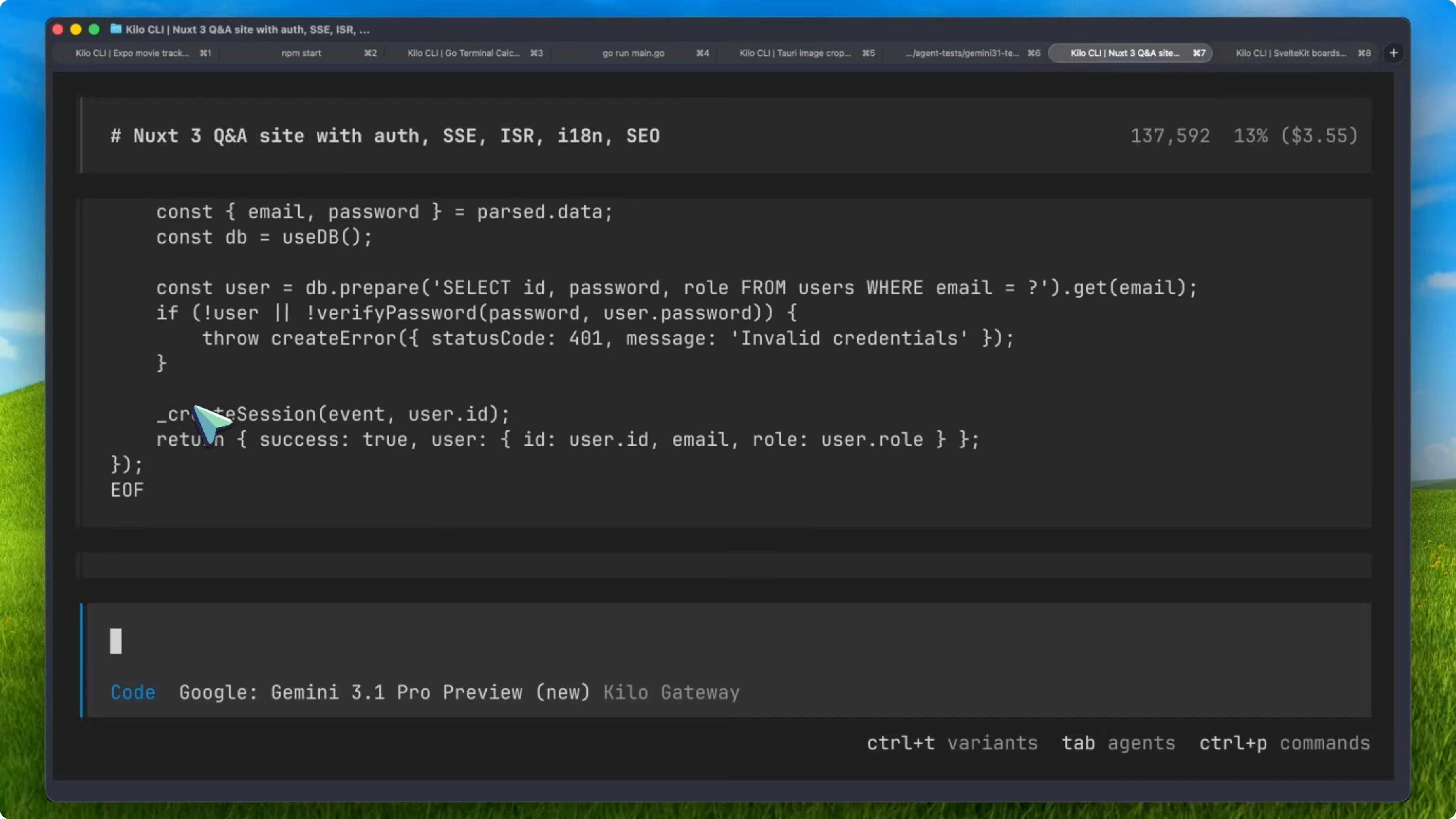
Fixing package names
Install the correct Svelte drag-and-drop package.
npm uninstall dnd-action
npm install svelte-dnd-action
Add Playwright with the proper name.
npm install -D playwright
Fix duplicated Go methods by keeping a single Update on your model.
package main
type Model struct {
// fields...
}
func (m *Model) Update(msg Msg) {
// update logic...
}
If you need a quick workaround for Gemini 3.1 Pro oddities, see this simple fix.
Tool usage comparison
If you compare this behavior to Claude or even GLM, those models just get to work. Sonnet 4.6 on Kilo Code reads the prompt, checks the environment quickly, and starts building. That is why it is at 87.9 on my agent leaderboard.
It actually uses the tools properly. It asks questions when it needs to using the right tool and does not repeat itself in thinking. That difference shows up clearly in performance and cost.
For more about me and these benchmarks, see about.
For context, Gemini 3.1 Pro with Kilo CLI is at rank 19 with 49.2. The older Gemini 3 Pro Preview with Kilo Code scored 71.4 at rank 7, and Gemini 3 Pro with Gemini CLI scored 61.7 at rank 13. Cursor with Gemini 3 Pro Preview scored 45.6 at rank 20, and anti-gravity with Gemini 3 Pro came in at rank 28 with 32.9.
Pricing
Gemini 3.1 Pro costs $2 per million input tokens and $12 per million output tokens. That is the same as Gemini 3 Pro, so no price increase. The question is whether it is worth paying for.
If you are using the Gemini API and paying for it, I do not see a strong reason to pick Gemini 3.1 Pro over the alternatives. Claude Opus 4.6 is more expensive, but it scores 100 percent on Kingbench and leads on agentic tasks. Sonnet 4.6 is cheaper and is the number one agent on my leaderboard.
GLM5 costs almost nothing and scores 79 percent on oneshot and 84.1 on agents. Even GPT 5.2 has better agentic performance in many setups. The only real use case I see for Gemini 3.1 Pro is through free tiers.
Gemini CLI gives you free access and Google anti-gravity also has free limits. In those scenarios, it is a great model because you are not paying anything. Free is free, and 96 percent on oneshot tasks for free is obviously fantastic.
Benchmarks vs reality
On industry benchmarks, Google is claiming strong numbers. It reports 80.6 percent on SWEBench verified, 68.5 percent on TerminalBench 2.0, and 33.5 percent on APEX agents. Those are good scores.
But SWEBench and those datasets are different from real projects. Benchmarks do not always translate to actual coding performance. In my real testing with Kingbench, which checks actual coding output quality and general intelligence, Gemini 3.1 Pro could not beat its predecessor.
In an agentic environment with multi-step tasks, the issues become obvious. The excessive planning, the poor tool usage, the redundant thinking that wastes tokens, and the typos in package names all hurt. These are the kinds of problems that matter when you are actually building something.
Verdict
Gemini 3.1 Pro is worse than Gemini 3 Pro in most ways that matter. It regressed on my oneshot benchmark from 100 to 96 percent while costing double. On the agentic side, it went from 71.4 down to 49.2, a 22 point drop, and fell from rank 7 to rank 19.
In an agentic environment, it plans forever, does not use tools properly, repeats itself in thinking, and makes avoidable coding mistakes. In a world where Claude, OpenAI, and GLM exist, paying for this model does not make much sense. If you are on the free tier through Gemini CLI or anti-gravity, use it, but if you are paying, I would look at Sonnet 4.6, Opus 4.6, or GLM5 first.
My setup
I am going to keep using Verdant with Sonnet 4.6 for most of my work. It is faster, uses tools correctly, and gets the job done without wasting time planning for 2 minutes. For more complex work where I need extra intelligence, I will use Opus 4.6.
Between those two, I have everything covered. I do not see any reason to switch to Gemini 3.1 Pro for my workflows right now. That is my honest opinion.
Final thoughts
Gemini 3.1 Pro looks strong on paper, but the real-world results do not back it up. The planning loops, tool misuse, and coding slips undermine its value, especially when you are paying by the token. Free-tier usage is fine, but for paid work, better options are already here.
Recent Posts
![How To Delete a Link In Google Chrome [2026 Guide]](/placeholder.png)
How To Delete a Link In Google Chrome [2026 Guide]
How To Delete a Link In Google Chrome [2026 Guide]
How To Fix Paused Problem In Chrome Browser [2026 Guide]
How To Fix Paused Problem In Chrome Browser [2026 Guide]
How To Put Your Image On Google Chrome Home Page As Background [2026 Guide]
How To Put Your Image On Google Chrome Home Page As Background [2026 Guide]