GLM-5 Review: Early Access Shows It Outperforms 4.6 Opus

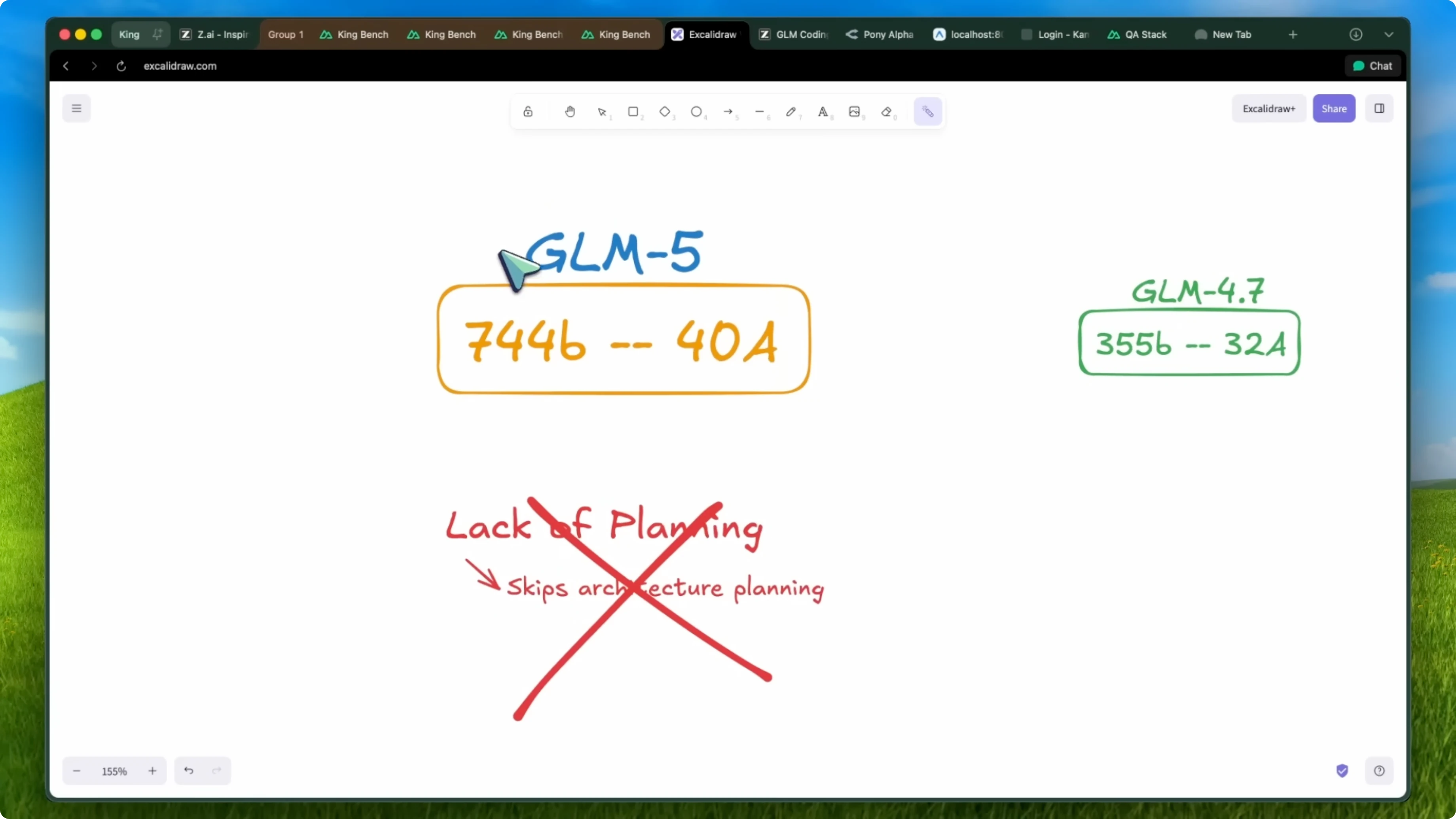
I have been using GLM5 for more than a week and it's an awesome model. This is a 744 billion parameter model that is a mixture of experts. Only 40 billion parameters are activated in usage.
For context, the previous GLM4 series models were about 355 billion parameters with 32B active in a pass, which was relatively small. One of the biggest open models is still Kimi with a trillion parameters, but GLM is now close, too. I don't have info about the API pricing at the time of testing, but there is supposed to be an increase in the API cost considering that the parameters are now almost double.
The coding plans should remain at the same price. Considering the improvement and relatively low cost, even after the increase, it is pretty good. It will also be open weights.
It is mostly the same model that we saw as Pony Alpha on OpenRouter. This will be a bit better as this is a final checkpoint. It is a reasoning model with effort that goes up to x-high and the reasoning tokens are available in the API as well.
It is relatively fast, though I was one of the few testers, so the speed may vary. Generally they get good speeds based on what I have seen with the last models as well.
GLM-5 Review: capabilities and goals
They were not able to give me a proper brief document because they are working hard on it. They do not do benchmarks until they have the exact production API that will go out to users because they say benchmarks need to align with what users feel. This is what they said in 2026: “Coding LLMs are evolving from simply writing code to building systems and GLM5 stands as the first open-source system architect model akin to Claude Opus. Our goal is to shift the narrative from a focus on front-end aesthetics to agentic engineering capabilities.”
I fully agree after seeing what this model is capable of. I think it is really akin to Claude 4.5 Opus or even 4.6 Opus. It is almost like a combination of CodeX and Opus if that makes sense.
For deeper context on this matchup, see GLM-5 vs Opus.
Planning and debugging
Some of the features that GLM4.7 lacked were planning and debugging. Whenever you asked the model to plan or debug, it was not good at it and it would skip some stuff. It could not grasp the whole architecture of a product and also lacked in long running tasks where it forgot about some change and in worst cases it even forgot about tools.
Considering that the model size has gone up, it seems now not just better but almost like Opus or CodeX in planning. If you put it in plan mode in something like OpenCode or Kilo Codes, it is actually good. It goes through, checks the files, does a system architecture check, and then proposes a plan.
It is now great with follow-up questions. It asks you what you exactly need if it gets confused or your prompt is not good, which is something previous GLM models lacked. They stuck with what you prompted once and just worked around that without asking, but this one is much better in that area.
Long tasks and instruction-following
It is better in long running tasks. GLM4.7 was also good in that area, but this one almost doubles down on that. I think that the new Opus 4.6 has regressed in this area, while CodeX has improved, and this feels better than both for me in long tasks.
It does not rush to finish tasks. It looks at linting errors and fixes them if it finds any. I have also seen that it adheres to the given instructions correctly and aligns itself with what the user requires much better than previous models.
GLM-5 Review: downsides
This is a model that is not very good with chats. I am not talking about general agent functionalities, which are great with OpenClaw and everything. I am talking about just textual chat and it is not great with that.
It is also not great with those HTML and SVG generations. To be honest, I am fine with that trade-off. The issue is actually that it tries to be too good because it is trained on so much code and system architecture, and it tries to think a lot about simple questions.
That hampers its performance in smaller tasks, especially those which do not involve using tools or stuff that does not have a derivative outcome. It struggles there. This aligns with their aim to be a system architect model and not a front-end gimmick model.
This behavior is akin to CodeX, as CodeX crashes in smaller tasks while it excels in bigger tasks. However, this one strikes a good balance of overall being good. In my benchmarks, it scores the third position.
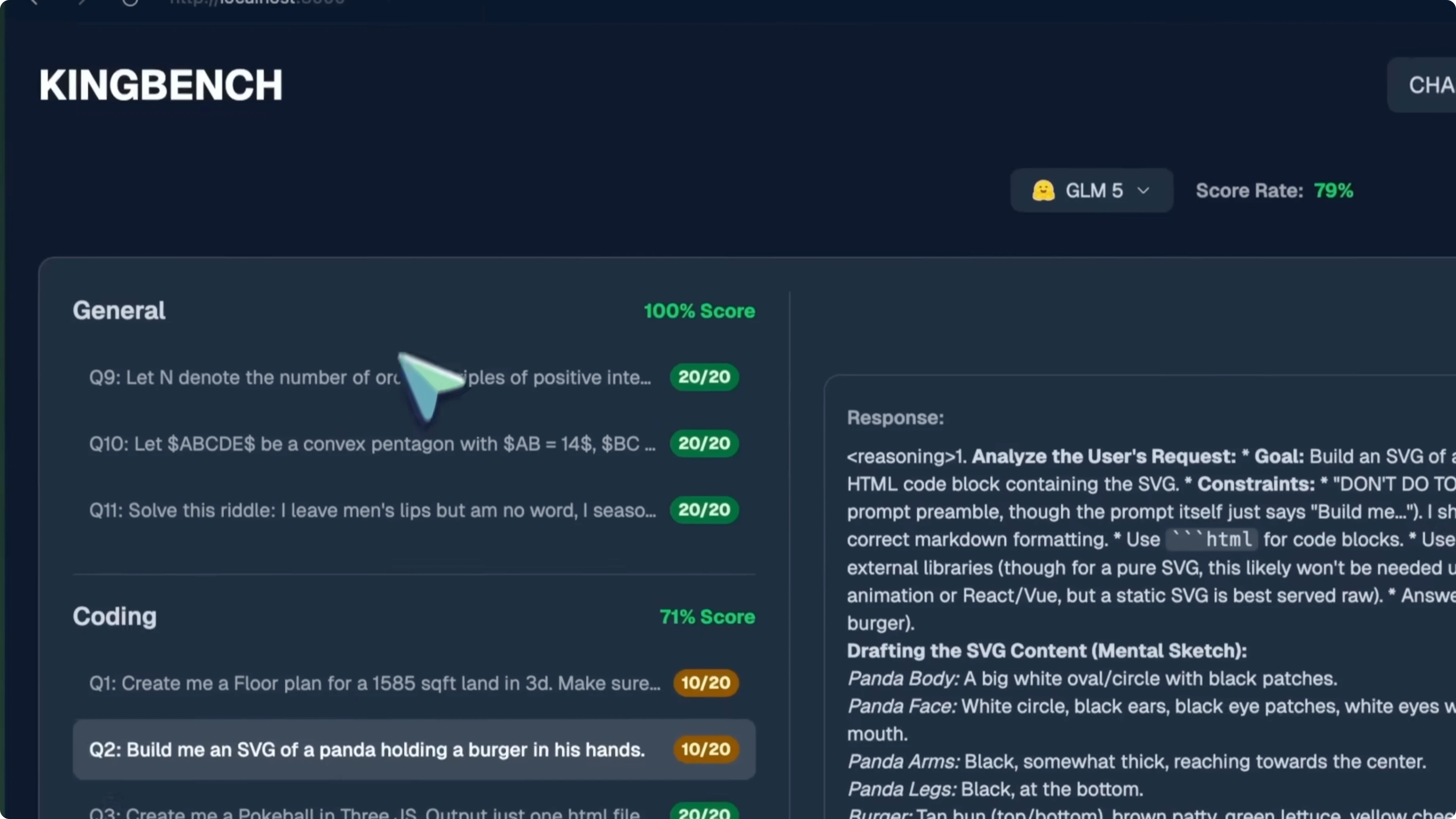
GLM-5 Review: benchmarks
The floor plan looked fine, had the toggle roof and everything, and it worked well. The architecture itself was not very nice and it lacked some necessary stuff that a floor plan should have. I kept it at a 10.
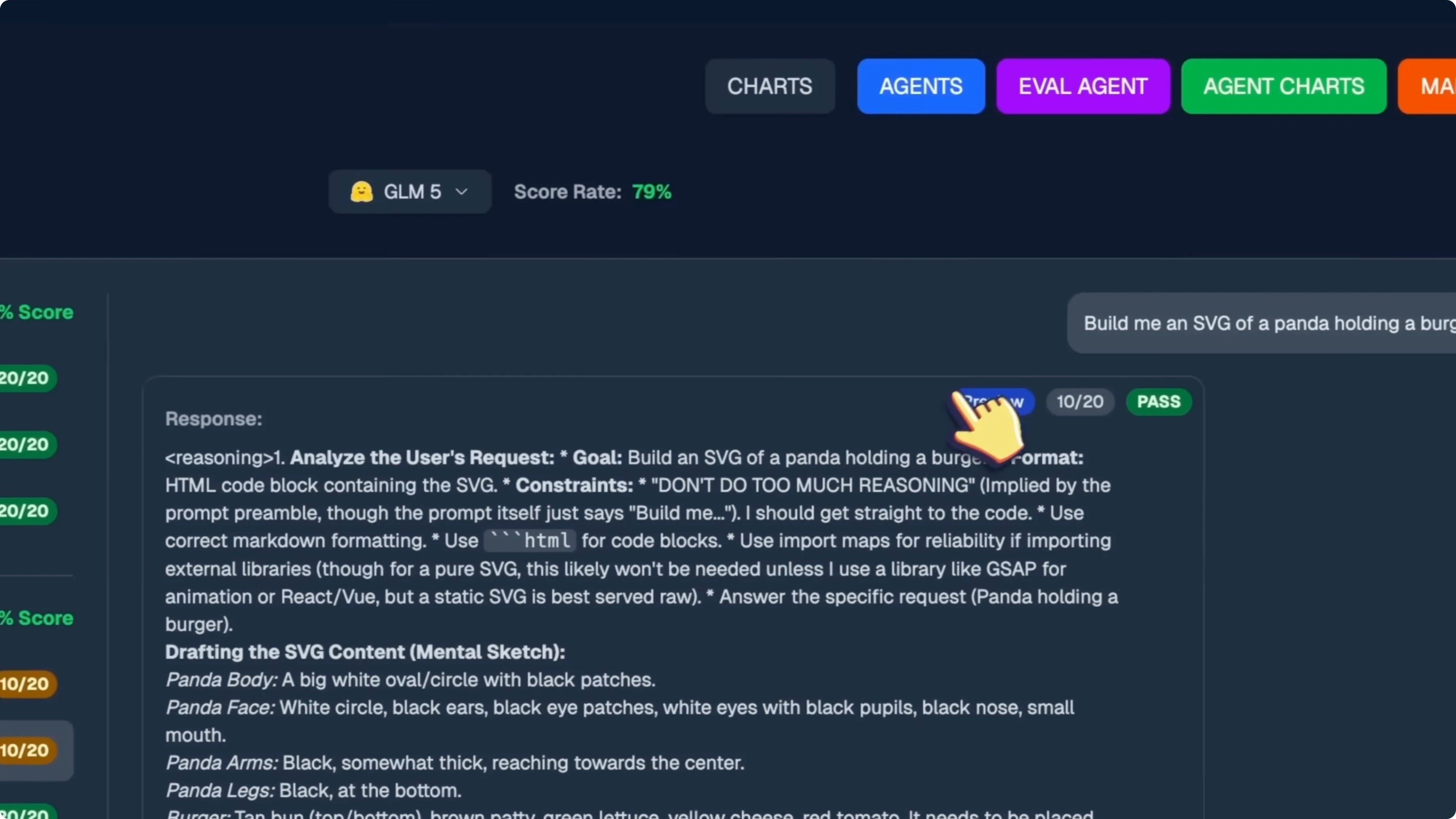
The SVG of a panda holding a burger is not the best by any means, but still relatively better than previous generations. That is a 10 out of 20. The Pokeball in Three.js works really well, you can click it and it opens up, and you can shake it as well.
There is nothing more that I could want given the prompt, so this is a 20. The chessboard with autoplay works really well. The autoplay is good and makes logical moves.

However, it moves the window of the board when a piece is there, which is not very good. So this is a 15. The Minecraft game was also really awesome and worked really well, but it still had some bugs, so it is a 15.
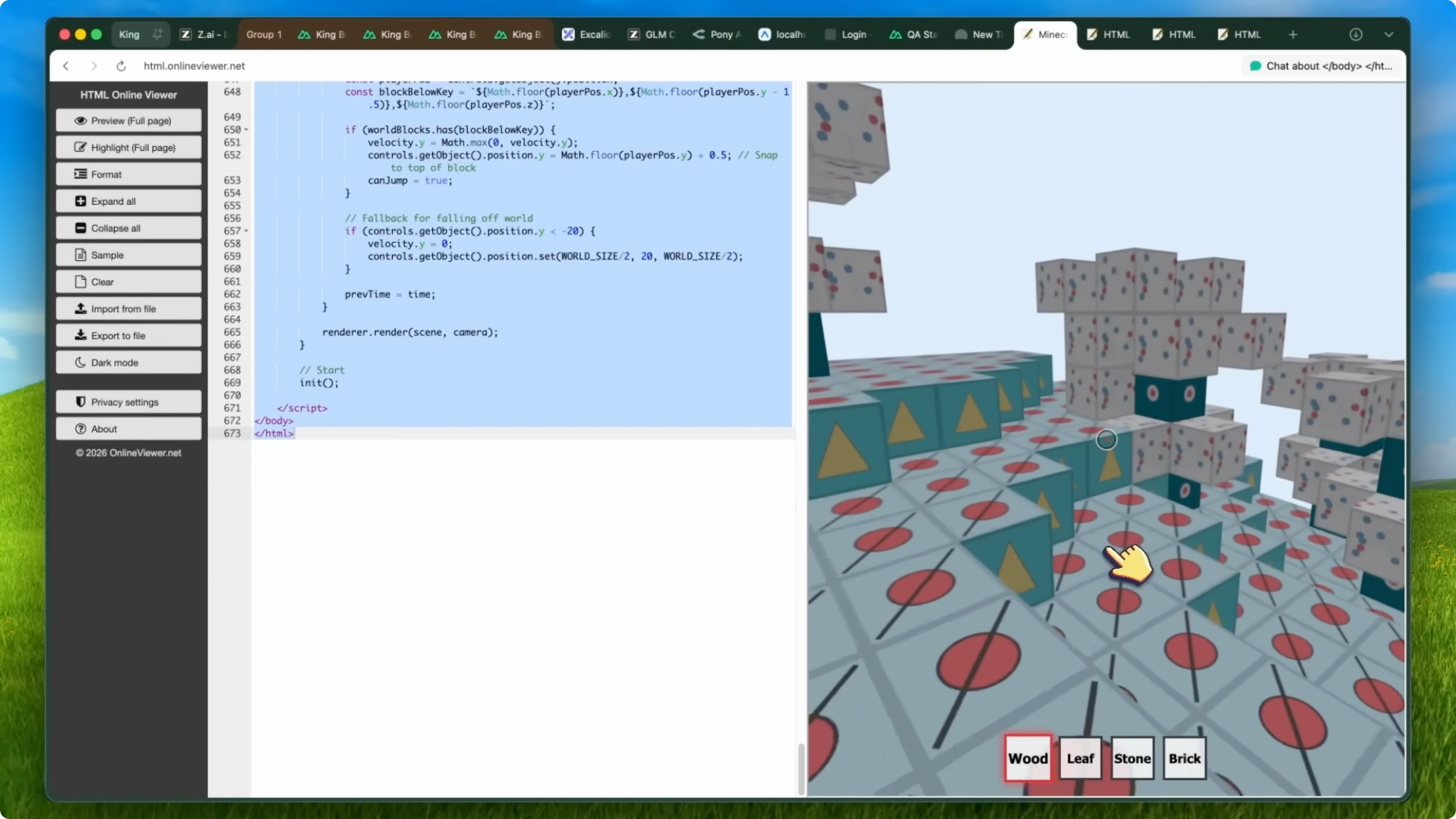
The butterfly flying in the garden is actually very good. It sets up the stage correctly and everything. The maths questions are also answered fully correctly, so it is a 20 out of 20 there as well.
This makes it score the third position, as I said.
Read More: Minimax M2.5
GLM-5 Review: agentic tests
I used it with the Kilo CLI as I was testing it at that time and it is pretty good. You should find the model in the Kilo Gateway and you should be able to set it up via the GLM coding plan. I asked them to fix Kilo CLI a bit for better usage with GLM5, so you should have a really good experience with it as well.
Setup in Kilo CLI
Find the model in the Kilo Gateway.
Set it up via the GLM coding plan.
Read More: Gemini 3.1 + GLM-5
Projects
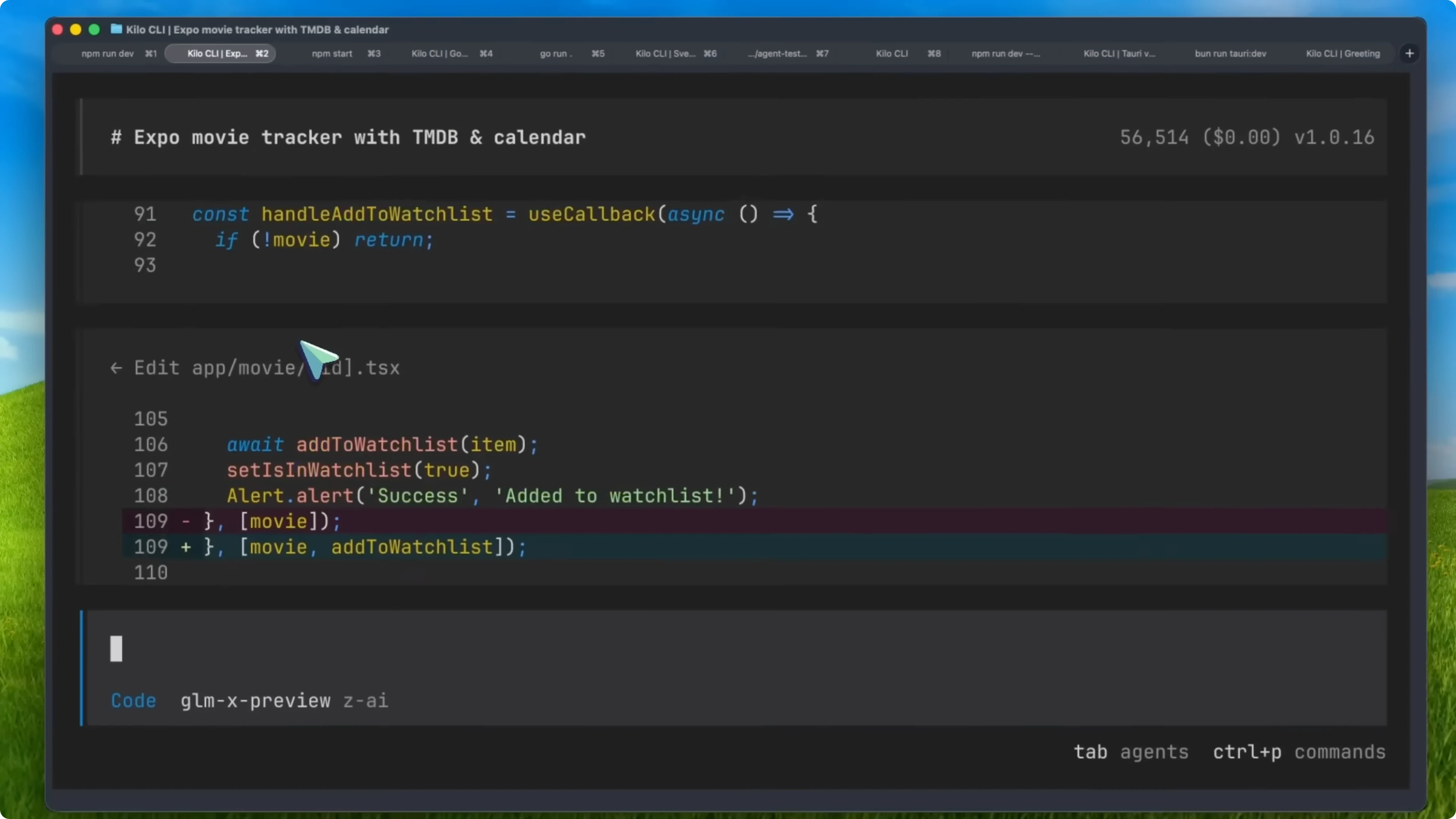
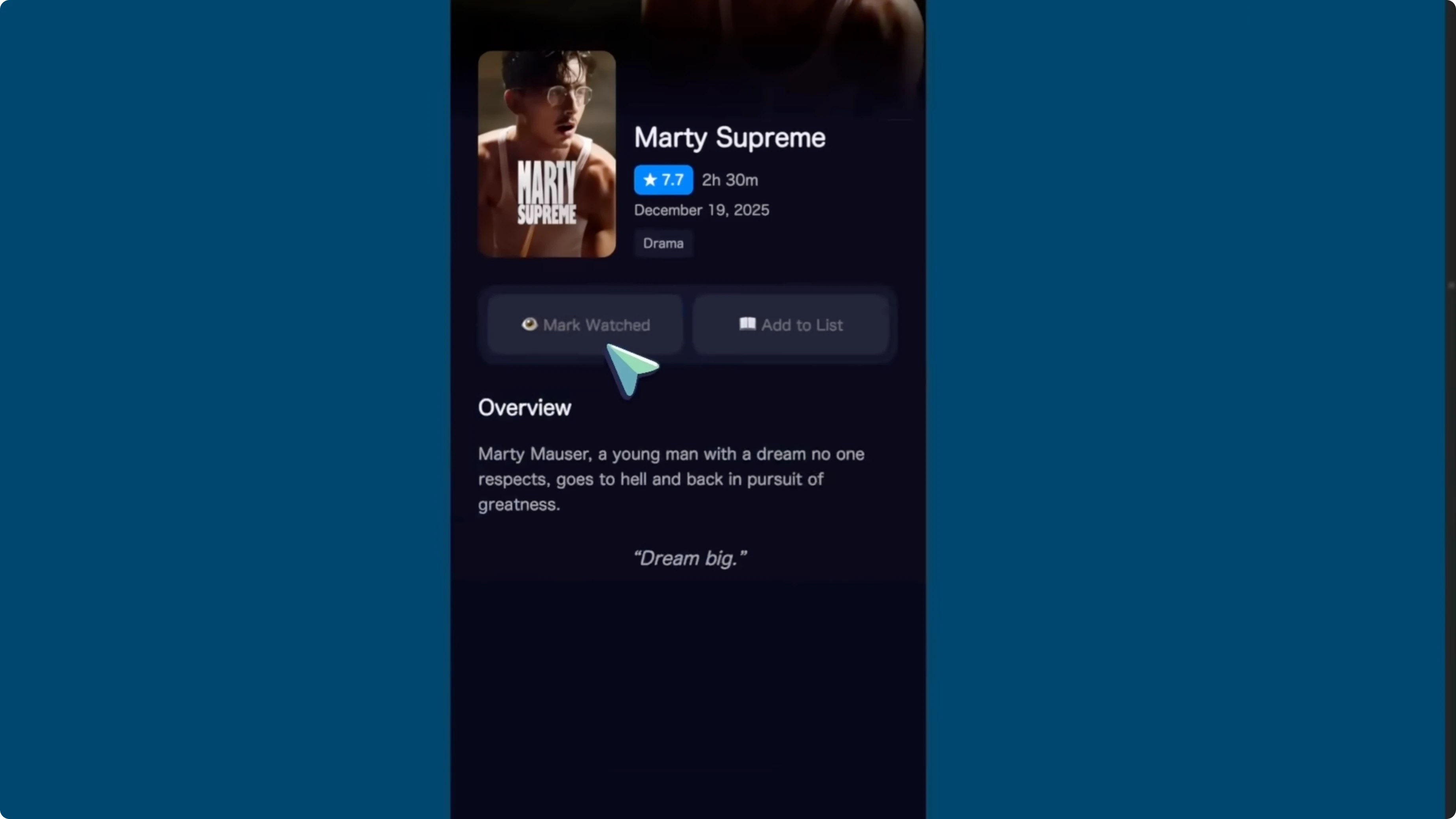
Movie tracker with Expo
The movie tracker app using Expo is one of the best recent generations I have seen. It is much better working than what even Opus makes for me and it went on for about 40 minutes to accomplish this. It fixed a lot of stuff as well.
It ran lint to check for errors and fixed them. It also used curl commands to check if there are any front-end errors, which is a very interesting thing I have not really seen with other models. The final result is fully functional and works amazingly well from one prompt.
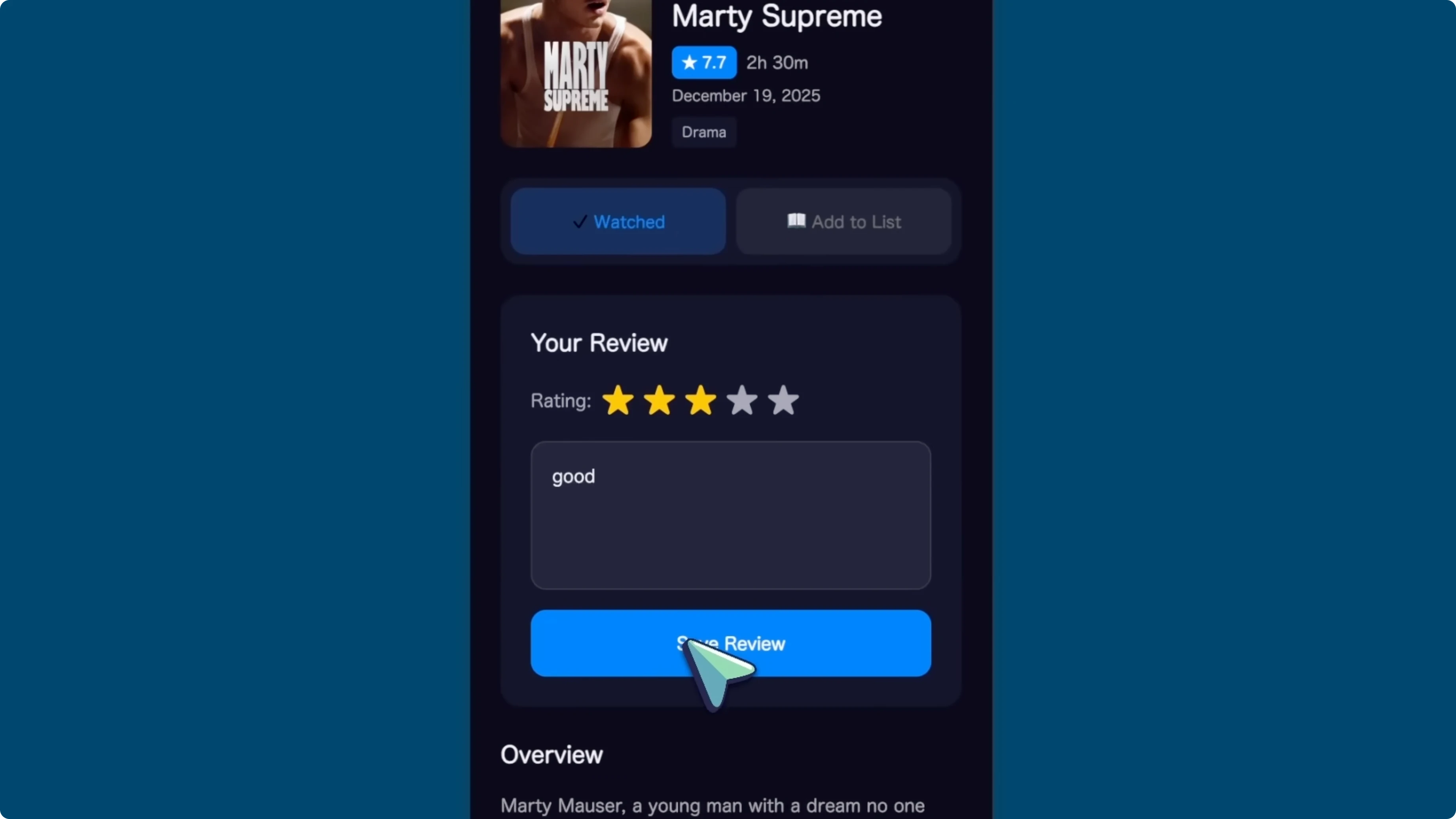
Even Opus generations have issues while this one is mostly perfect with good design. This is great.
Go-based terminal calculator
The Go based terminal calculator is objectively better than the last Opus 4.6 generation I saw and also better than CodeX. It is quite good.
God game
The God game was good. It is something most models can now do and I am glad they have added support for it.
Svelte Kanban app
I asked it to build me a Svelte Kanban app with a database and it did that quite well. It works really well. Even Opus does not do it well and CodeX is also not that great, so this is great to see.
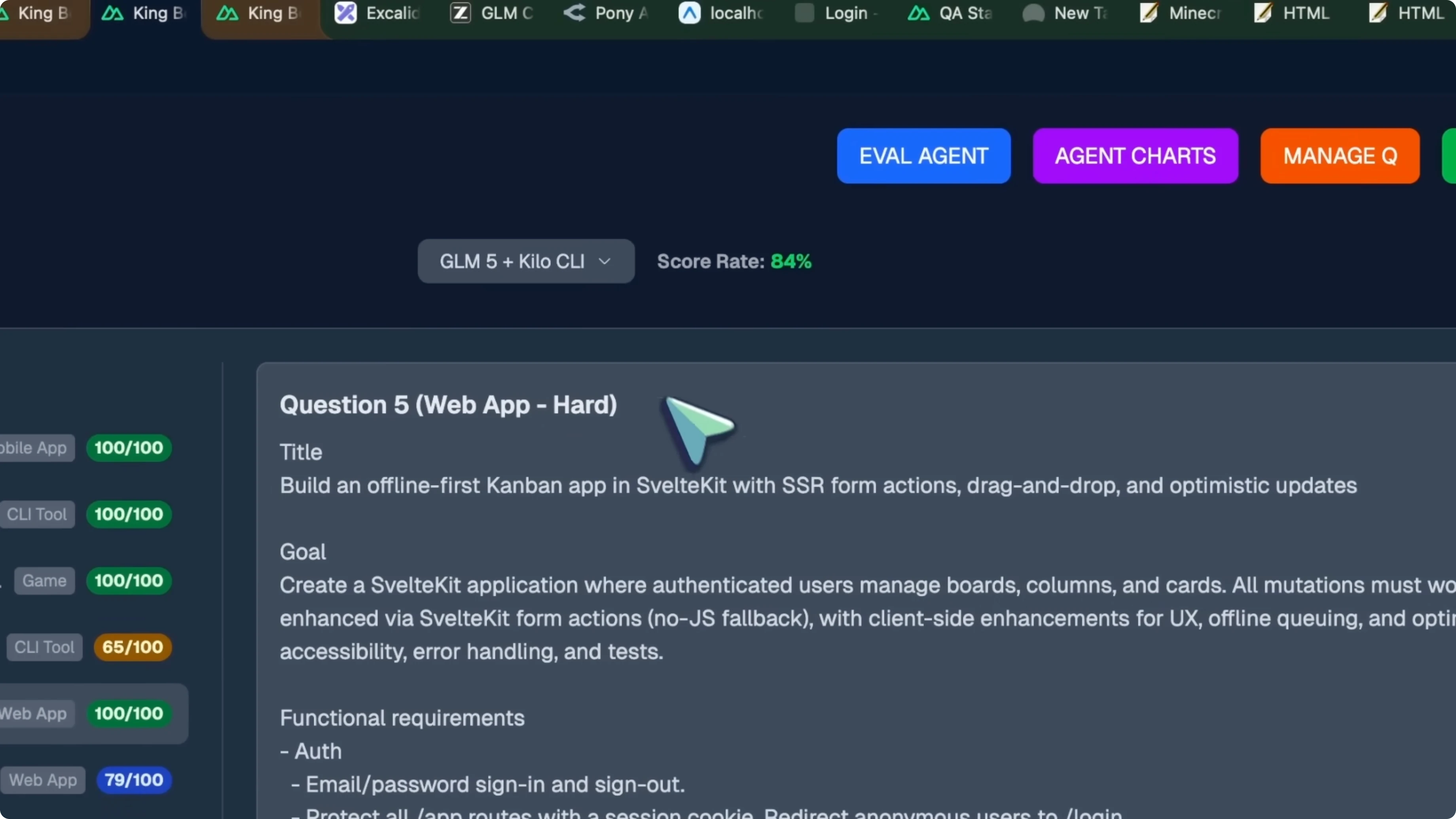
Nuxt Stack Overflow clone
The Nuxt app, which should be a Stack Overflow clone, worked quite well. It is really good and you can see the threads, make stuff, and everything. It is genuinely better than Opus 4.6 generations.
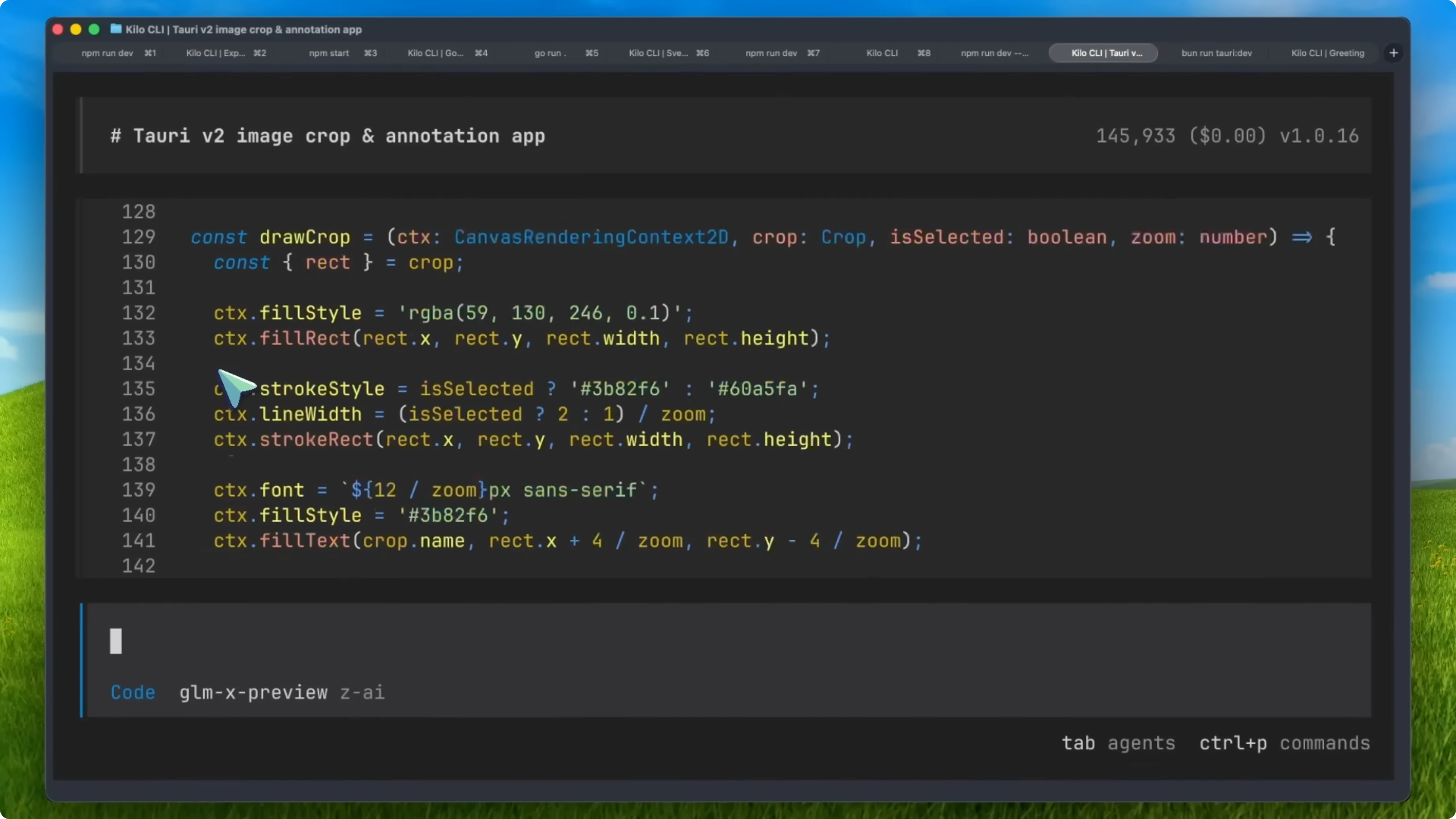
Tauri image editor
The Tauri app was interesting. It went on for more than 3 hours on a very complex task to make an image cropper and editor tool with AI features for automatic subject selection. It kind of works, but it does have bugs.
GLM-5 Review: leaderboard and pricing
This model is very good. It scores the number one position on my agentic leaderboard. It completes each task and all of them actually work.
The code quality is really good and it does not stop until it finishes. It does not do weird things to save tokens which penalizes performance. I am preferring to use this in coding agents over Opus, which says a lot about this model.
You can check it out as well. It is going to be way cheaper than Opus and Open, which is awesome. You might feel at first that it is doing some mistakes, but with good steering, it is awesome.
This will probably be the model I use from now on. You can use it with OpenClaw as well and their coding plan is pretty cheap. Overall, it is pretty cool.
Final thoughts
GLM5 pushes into system architect territory with strong planning, long task reliability, and persistent error fixing. It lags in pure textual chat and front-end SVG or HTML outputs, but it makes up for that by executing complex, multi-step builds that finish cleanly. It ranks third on my benchmarks and first on my agentic leaderboard, and I prefer it over Opus 4.6 and CodeX for coding agents.
Recent Posts
![How To Fix Your Connection Is Not Private In Google Chrome [2026 Guide]](/how-to-fix-your-connection-is-not-private-in-google-chrome-2026-guide.webp)
How To Fix Your Connection Is Not Private In Google Chrome [2026 Guide]
How To Fix Your Connection Is Not Private In Google Chrome [2026 Guide]
![How To Access Extension in Google Chrome [2026 Guide]](/how-to-access-extension-in-google-chrome-2026-guide.webp)
How To Access Extension in Google Chrome [2026 Guide]
How To Access Extension in Google Chrome [2026 Guide]
![How To Change Google Chrome Background [2026 Guide]](/how-to-change-google-chrome-background-2026-guide.webp)
How To Change Google Chrome Background [2026 Guide]
How To Change Google Chrome Background [2026 Guide]