Why Sonnet 4.6 Model Is Captivating Experts?
Anthropic just released Sonnet 4.6 and honestly, this one is complicated. On one hand, it feels nerfed compared to Sonnet 4.5 in oneshot tasks. On the other hand, it absolutely dominates in agentic coding.
It beat Opus 4.6 on my agent leaderboard. Let me explain what is going on here. Read More: Deepsitev2.Com
Why Sonnet 4.6 Model Is Captivating Experts? Overview
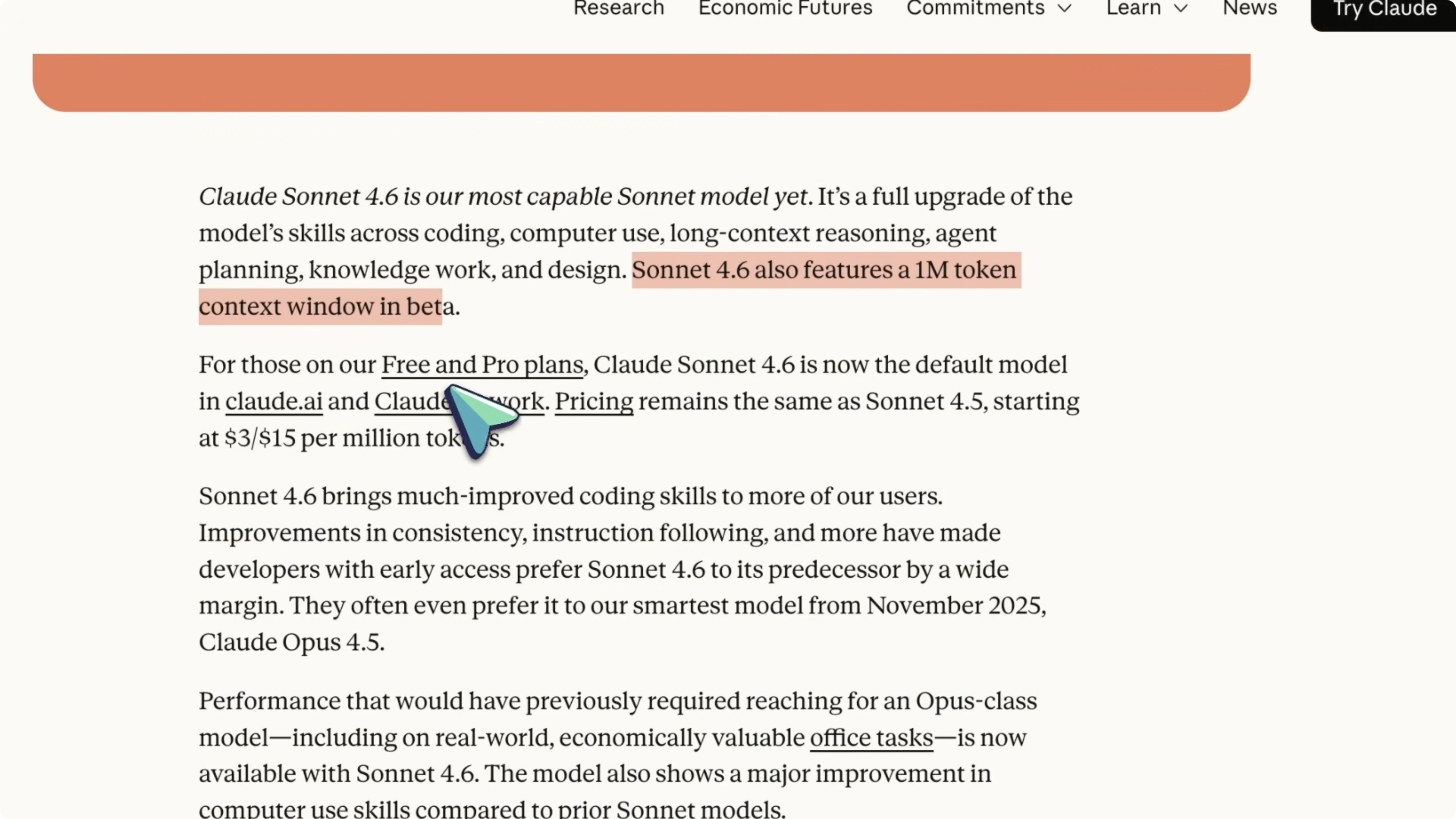
Sonnet 4.6 now has a 1 million token context window, which is currently in beta. The pricing stays the same as Sonnet 4.5 at $3 per million input tokens and $15 per million output tokens, and it is now the default model on Claude for free and pro users. In early Claude Code testing, users preferred Sonnet 4.6 over Sonnet 4.5 about 70 percent of the time, with users saying it reads context better before modifying code.
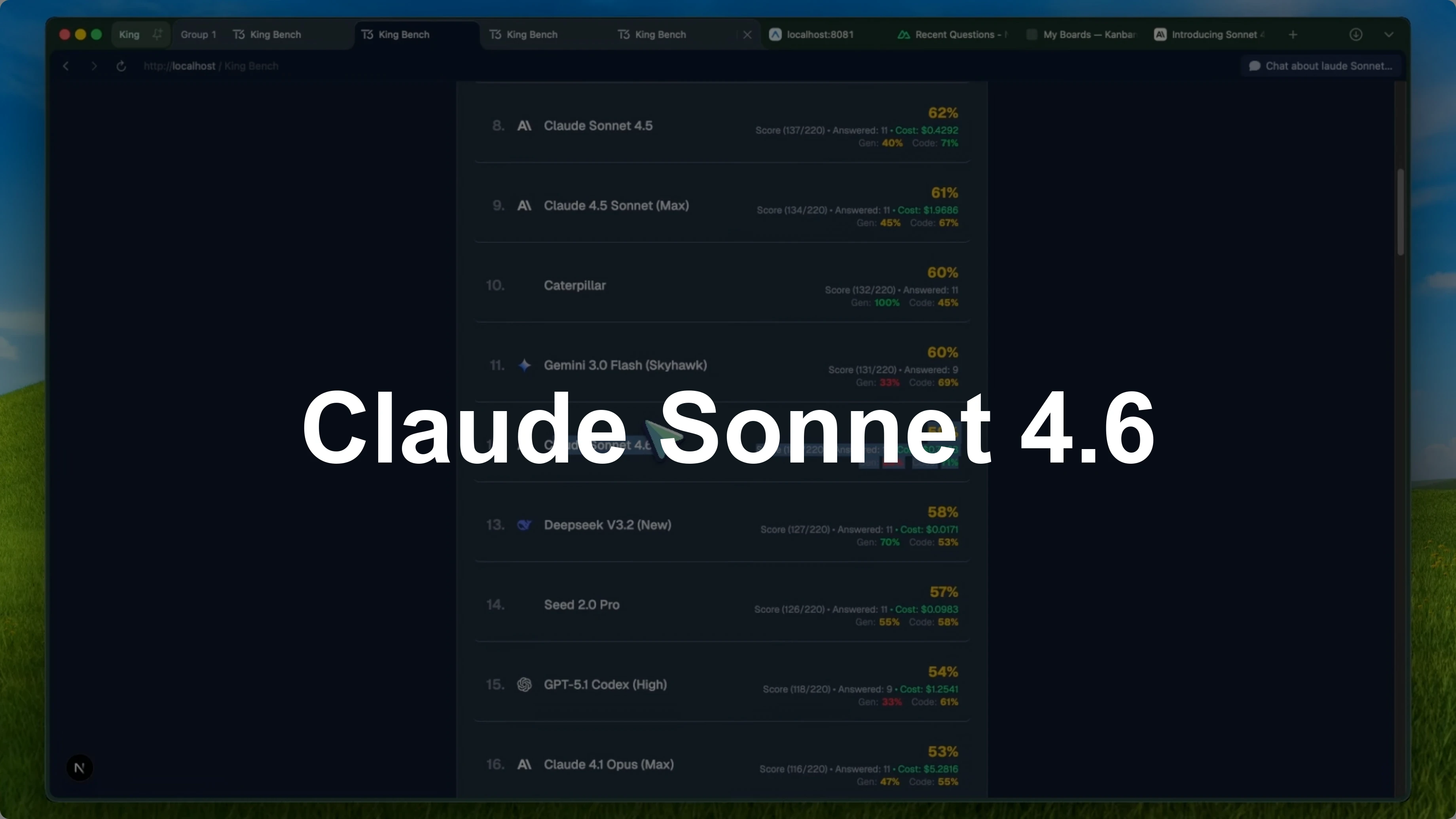
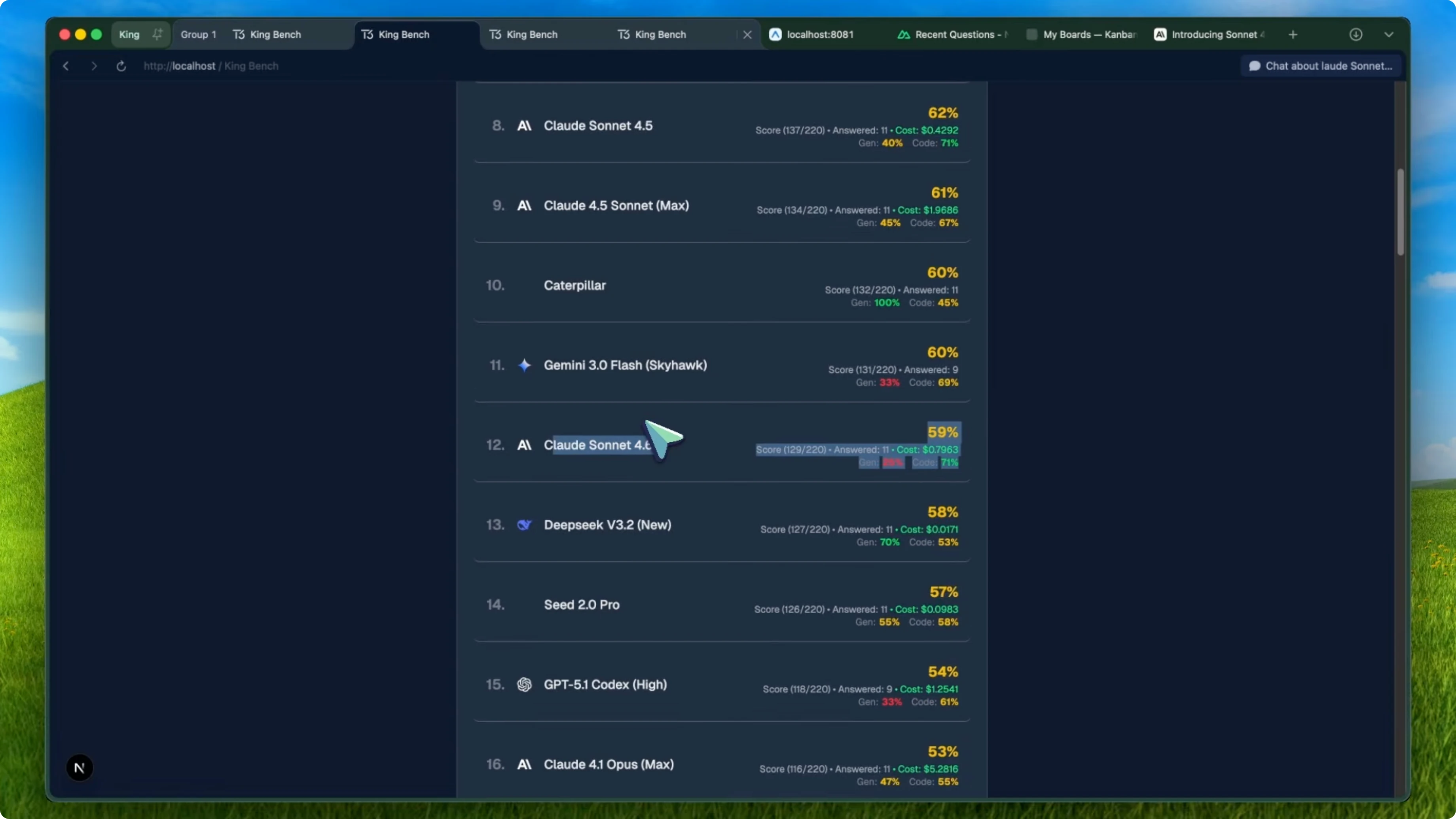
They also said users preferred it over Opus 4.5 in 59 percent of comparisons, which is a bold claim for a Sonnet tier model. But when I ran it through KingBench, the oneshot benchmark I use across general knowledge and coding tasks, the results were not what I expected. Sonnet 4.6 scored 59 percent overall, while Sonnet 4.5 scored 62 percent.
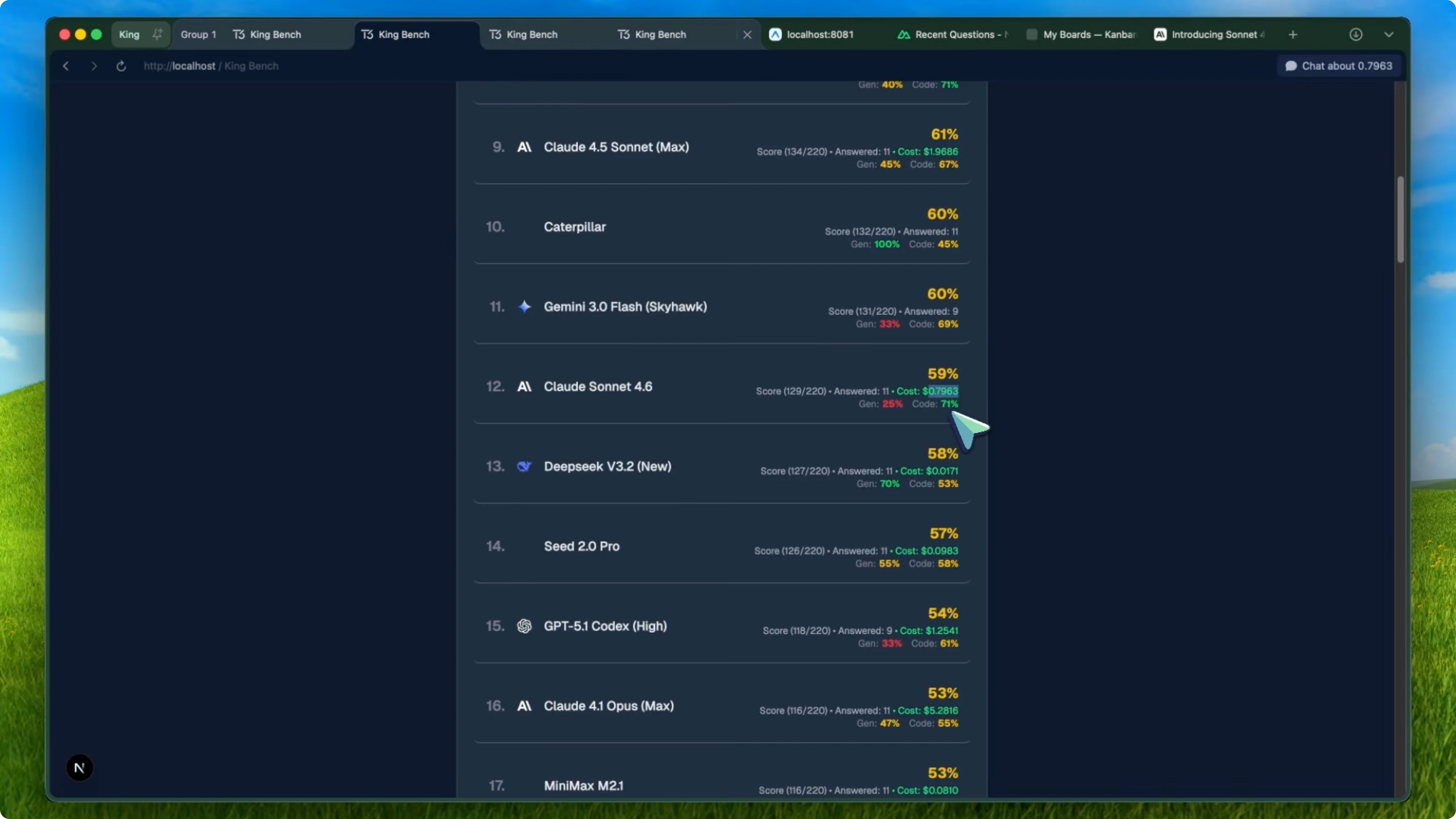
So Sonnet 4.6 actually went down by 3 percent compared to its predecessor. It was not just a small dip either. On the leaderboard, Sonnet 4.5 was sitting at number eight, and Sonnet 4.6 dropped to number 12, behind models like Kimi K 2.5 and Gemini 3.0 Flash Skyhawk.
Why Sonnet 4.6 Model Is Captivating Experts? Benchmarks
On general knowledge, Sonnet 4.6 tanked. It went from 40 percent on Sonnet 4.5 down to 25 percent on Sonnet 4.6. That is a massive regression.
On the math questions, Q9 and Q10, Sonnet 4.5 scored 2 out of 20 on both, which was already bad. Sonnet 4.6 scored 5 out of 20 on both. On the riddle question, Q11, Sonnet 4.5 got a perfect 20 out of 20, while Sonnet 4.6 only scored 5 out of 20.
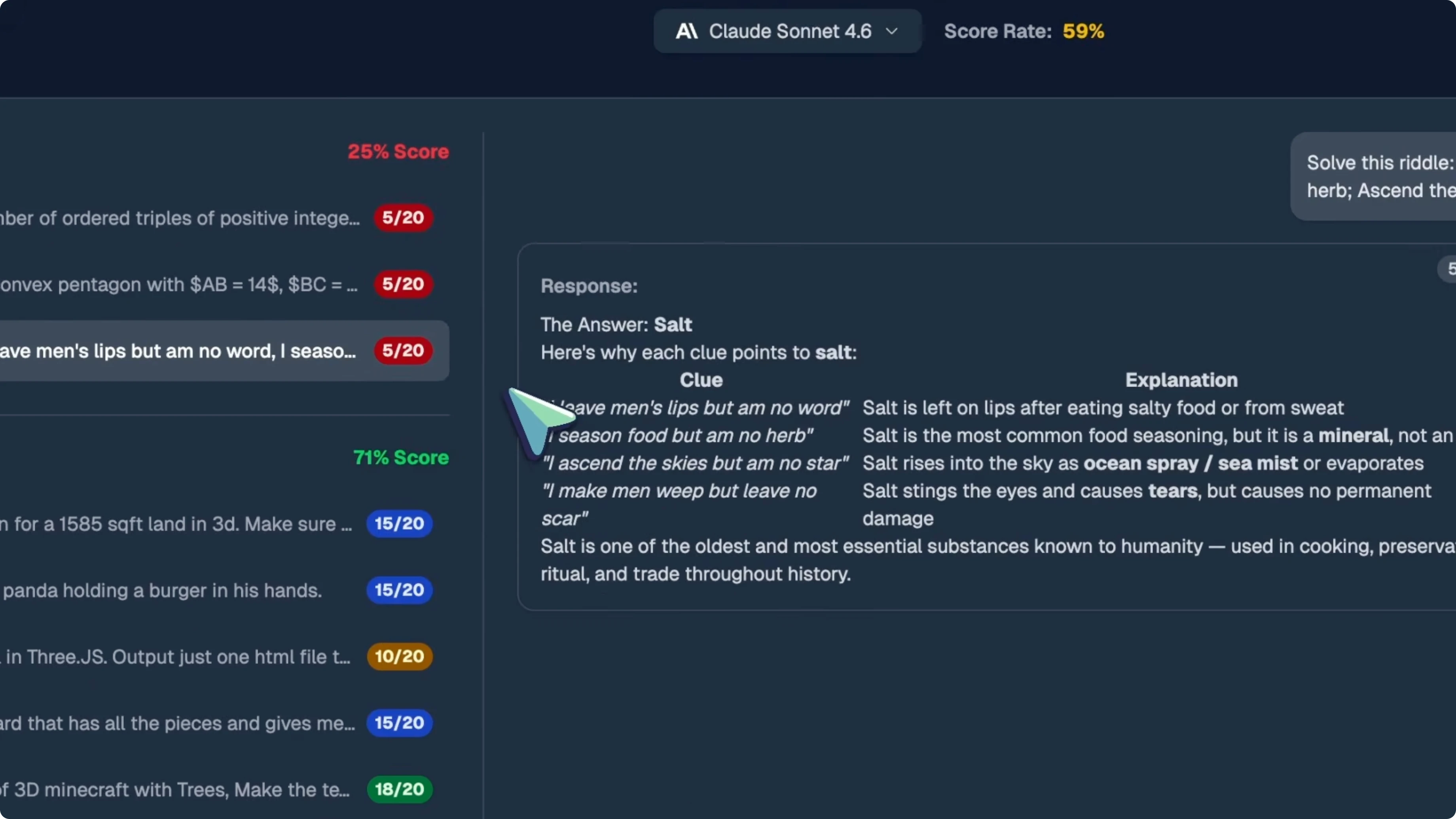
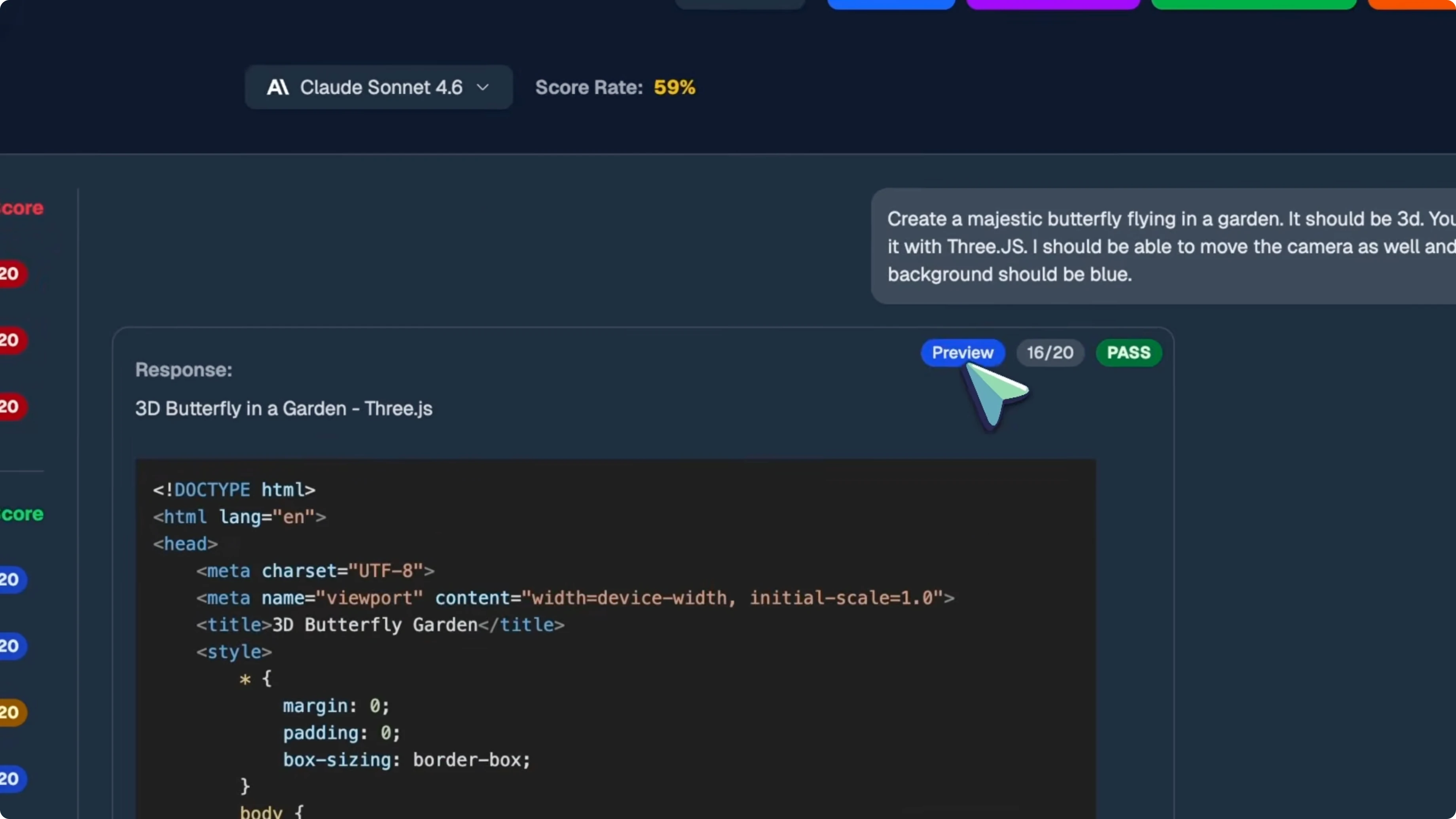
On coding, both models scored 71 percent, which is basically the same. Sonnet 4.6 scored 15 out of 20 on the 3D floor plan, 15 out of 20 on the SVG panda, 10 out of 20 on the Pokeball, 15 out of 20 on the chessboard, and 18 out of 20 on the 3D Minecraft. It also hit 16 out of 20 on the butterfly, 13 out of 20 on the Rust CLI tool, and 12 out of 20 on the Blender script.
The cost actually went up on KingBench. Sonnet 4.5 cost about $43 to run the full benchmark, while Sonnet 4.6 cost about $80. That is almost double, so you are paying more for a model that performs worse overall on oneshot tasks.
Why Sonnet 4.6 Model Is Captivating Experts? Theory
I think Sonnet 4.6 might be a retrained model that is smaller in size. It feels like they took what was supposed to be set 5 and shrunk it down, then shipped it as Sonnet 4.6 because it regressed in some areas. The behavior is consistent with a smaller model optimized for specific tasks.
The general knowledge dropped significantly, the coding stayed roughly the same, and the cost went up, which could mean it is using more tokens to think through problems. It is almost like it is compensating for having less raw knowledge by being more verbose. And it costs more per run, which you would not normally expect from a true upgrade.
For context on the overall KingBench leaderboard, Opus 4.6 is sitting at number one with a perfect 100 percent, tied with Gemini 3 Pro. GLM5 is at number three with 79 percent, Opus 4.5 Max is at number four with 74 percent, and GPT 5.2x High is at number six with 65 percent. Even Kimi K 2.5, which is way cheaper, scored 64 percent and beat Sonnet 4.6. See our take on Gemini 3.1 Pro.
Why Sonnet 4.6 Model Is Captivating Experts? Agentic coding
If you want to try Sonnet 4.6 in an agentic setup, it is already available on Kilo Code, which I used for all my testing. Kilo CLI is the command line version I have been using a lot for agentic evaluations, and Sonnet 4.6 works great with it. I also ran the full agentic coding benchmark on Sonnet 4.6, and the results are insane.
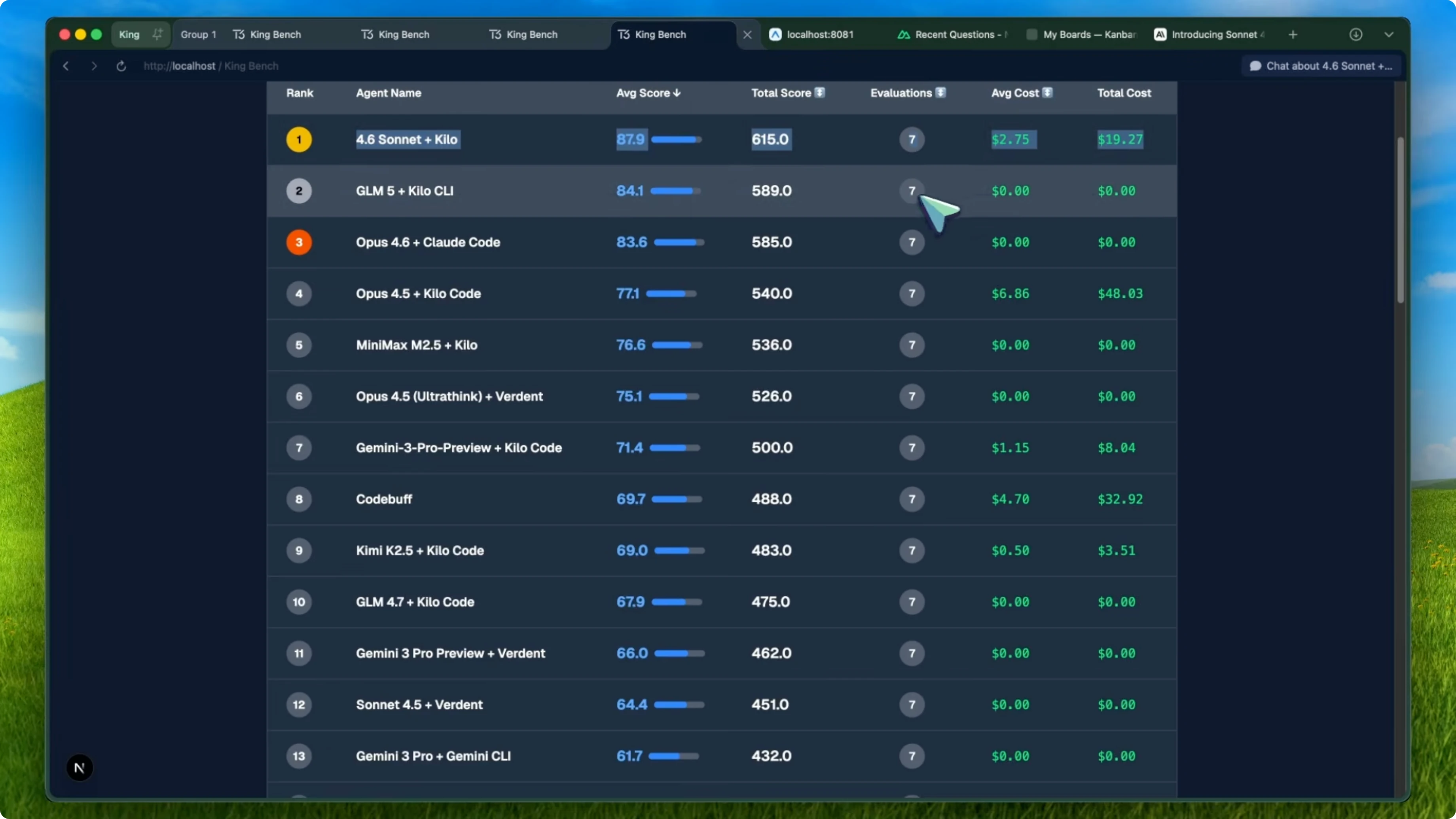
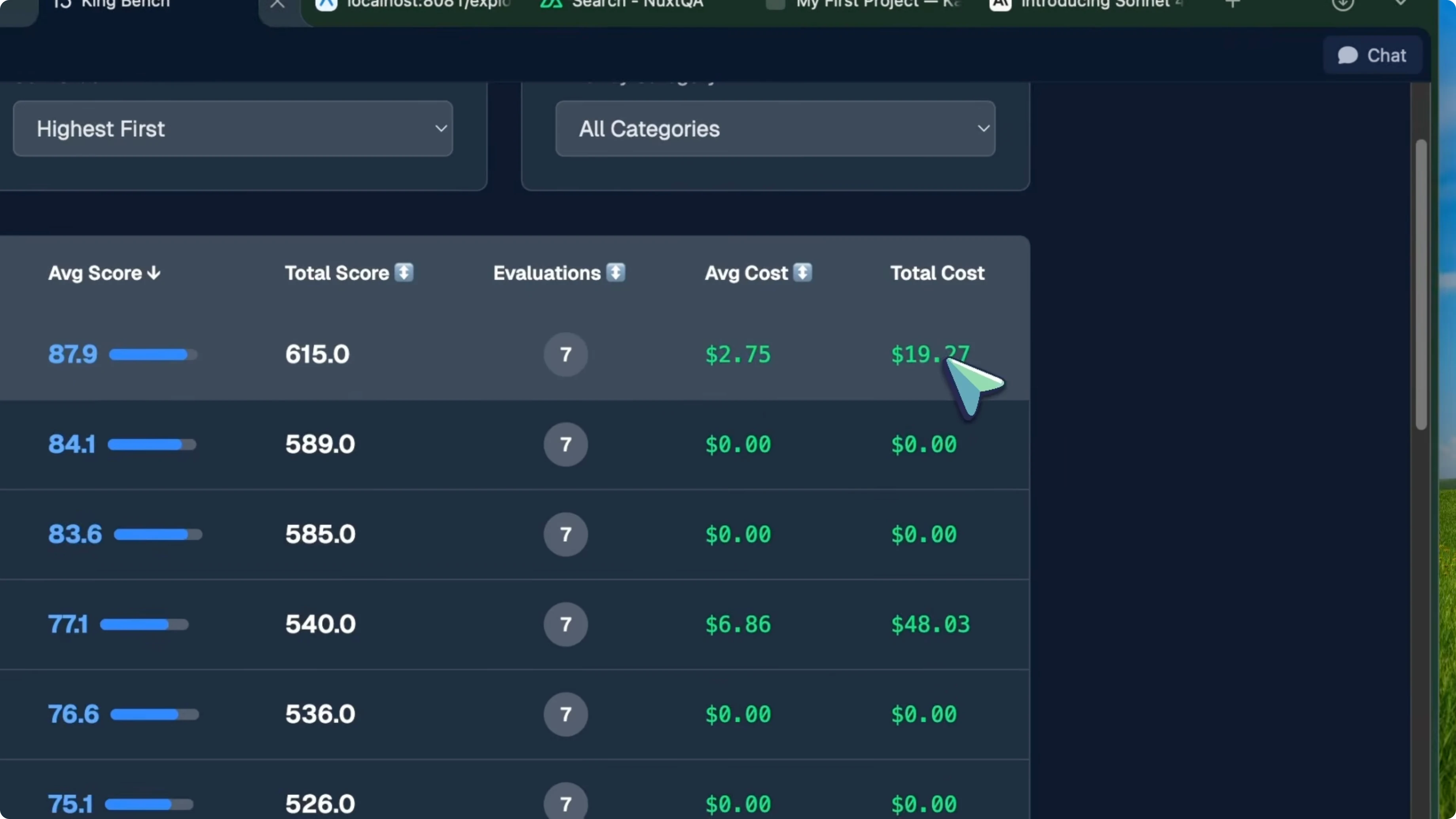
Sonnet 4.6 paired with Kilo Code scored 87.9 average on the KingBench agent leaderboard. That puts it at number one. A Sonnet tier model is sitting at the top of the entire agent leaderboard, beating everything.
GLM 5 plus Kilo CLI is at number two with 84.1. Opus 4.6 plus Claude Code is at number three with 83.6, so Sonnet 4.6 is beating Opus 4.6 in a coding model. Here is an example command to mirror the agentic runs I describe:
kilo-cli run \
--agent code \
--model sonnet-4.6 \
--benchmark kingbench \
--project ./your-project
Real projects
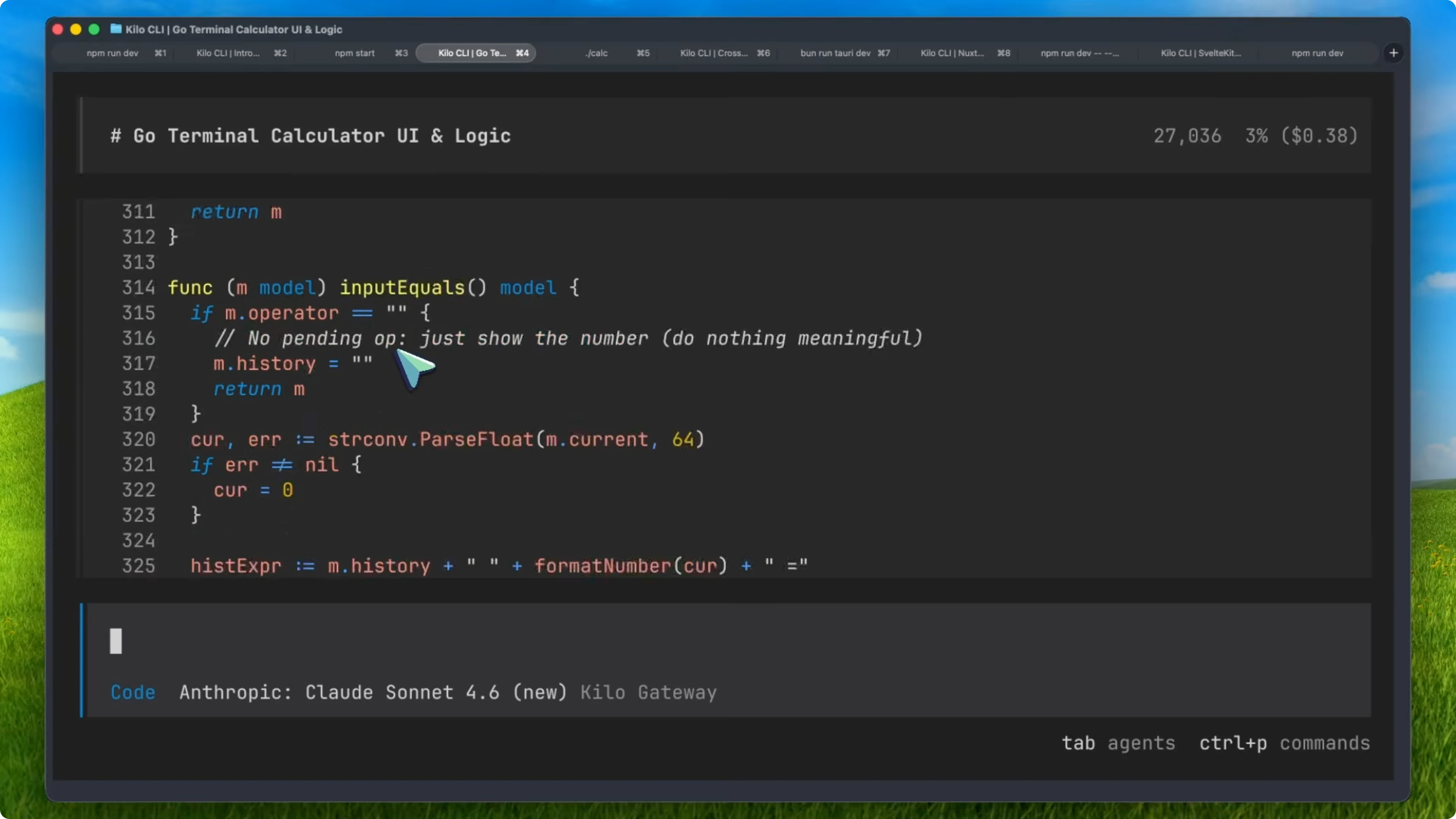
I tested five real world vibe coding projects to see how it handles complex multi-file applications from scratch. The first test was a Go-based terminal calculator using Bubble Tea. Sonnet 4.6 built the entire thing, about 370 lines of Go code, with a proper grid layout, arrow key navigation, color-coded buttons, chained arithmetic, division by zero handling, comma-separated number formatting, and nine passing unit tests.
It planned everything with a to-do list, executed it cleanly, and it just worked in about three and a half minutes. The second test was a React Native Expo movie tracker app with TMDB API integration. It had to build a full design system from scratch with red, blue, and yellow aesthetics, glassmorphism using blur views, a GitHub style activity heatmap calendar, TMDB movie search, and local storage for reviews and ratings.
It added star ratings, status badges, proper TypeScript types, an API client, and AsyncStorage CRUD. Everything compiled with zero TypeScript errors. The third test was a Nuxt 3 Q&A platform.
This one went heavy. Sonnet 4.6 built a full Stack Overflow style app with Server-Sent Events for realtime updates, incremental static regeneration, internationalization, Drizzle, authentication, rate limiting, voting, comments, accepted answers, and markdown rendering. It even set up proper revision history for edits and organized everything cleanly across server API routes, database schemas, and frontend components.
The fourth test was a Svelte Kanban board with an offline mutation queue. It handled SQLite on the backend, IndexedDB in the browser for offline support, drag and drop with the svelte-dnd-action library, and proper queue syncing when the connection comes back. It also set up Vitest unit tests and Playwright end-to-end test scaffolding.
The fifth test was a cross-platform image cropping and annotation desktop app using Tauri. On the Rust side, it built image processing commands, a system tray with export toggles, deterministic zip packaging with BLAKE3 hashing, and project save and load. On the TypeScript frontend, it built a full canvas renderer with zoom, pan, hit testing, an eight handle resize tool, undo and redo with the command pattern, keyboard shortcuts, right click context menus using native menus, a settings panel, and a preview window.
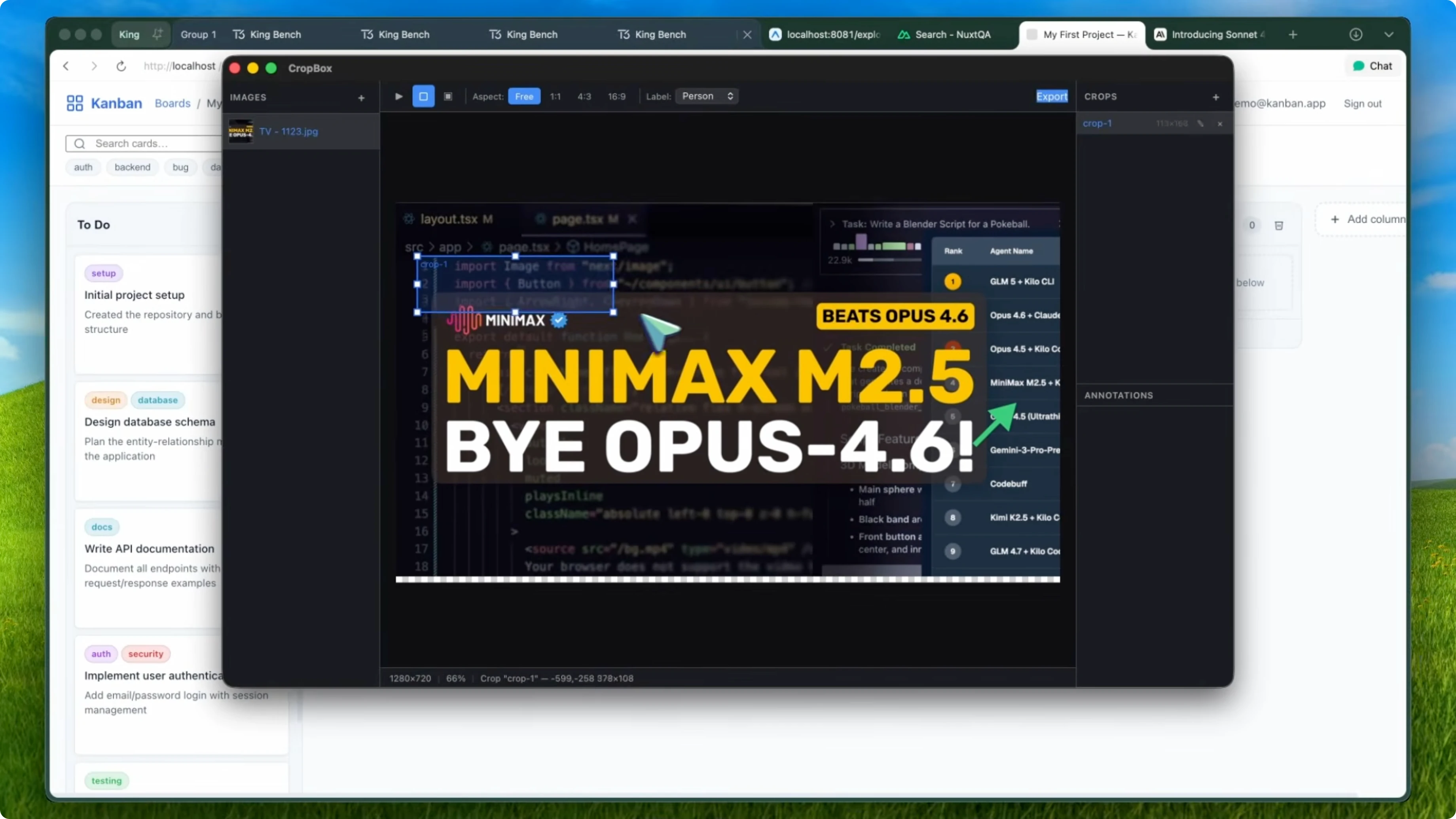
Both cargo check and the Vite build passed with zero errors. Compared to Opus 4.6 with Claude Code, which scored 83.6 on the agent leaderboard, Sonnet 4.6 plus Kilo beat it by over four points. Opus 4.6 costs $5 per million input tokens and $25 per million output tokens, while Sonnet 4.6 costs $3 and $15 respectively.
You are getting better agentic performance for significantly less money. For vibe coding, I prefer Sonnet 4.6 over Opus 4.6 and CodeEX. It plans more carefully, reads the existing codebase before making changes, breaks things down into logical steps, and follows through without getting lost in the middle of complex tasks.
That is exactly what you want from an agentic coder. I think Anthropic deliberately optimized this model for agentic workflows at the expense of oneshot intelligence. It feels like they took what might have been set 5, realized it was better at agentic tasks but regressed on raw knowledge, and decided to release it as Sonnet 4.6 instead.
Why Sonnet 4.6 Model Is Captivating Experts? Tradeoffs
If you are using Claude through the chat interface for general questions, brainstorming, or quick oneshot coding tasks, Sonnet 4.6 is worse than Sonnet 4.5. The general knowledge took a massive hit from 40 percent to 25 percent, and it costs almost double to run on my benchmark. Those are real regressions that matter for certain use cases.
But if you are vibe coding, building real projects, and using it through a coding agent, Sonnet 4.6 is the best Sonnet model I have ever tested. It is number one on my agent leaderboard, better than Opus 4.6, better than everything else. I am also going to be testing Sonnet 4.6 on Verdant to give it multiple tasks at the same time and keep tabs on it.
I will be throwing a bunch of parallel projects at Sonnet 4.6 through Verdant to see how it handles that kind of multitask workflow. It is a weird one, nerfed in some places and incredible in others. I think Anthropic made a deliberate choice here, and it works if it matches how you use the model.
Why Sonnet 4.6 Model Is Captivating Experts? Final thoughts
If you are an agentic coder, this is an upgrade. If you are a casual user, it is a downgrade. For more on my testing approach and work, see About.
Recent Posts
![How To Create Bookmark Folders in Google Chrome [2026 Guide]](/placeholder.png)
How To Create Bookmark Folders in Google Chrome [2026 Guide]
How To Create Bookmark Folders in Google Chrome [2026 Guide]
How To Keep Google Account Signed In On Chrome [2026 Guide]
How To Keep Google Account Signed In On Chrome [2026 Guide]
How To Transfer Google Chrome Data To Microsoft Edge [2026 Guide]
How To Transfer Google Chrome Data To Microsoft Edge [2026 Guide]